Documentation Index
Fetch the complete documentation index at: https://docs.conduktor.io/llms.txt
Use this file to discover all available pages before exploring further.
Pick your format wisely
This is the first thing to setup when you’re consuming a topic.
Key and Value
There are 2 formats to pick: the key format and the value format.- In most cases, the key is a String so nothing to worry about here. But Conduktor also support various formats
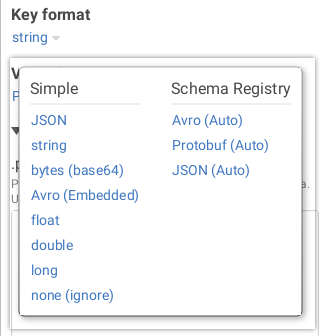
- The value is typically JSON or Avro or Protobuf but it can also be long, float or other primitives when working with Kafka Streams where you’re doing aggregations for instance
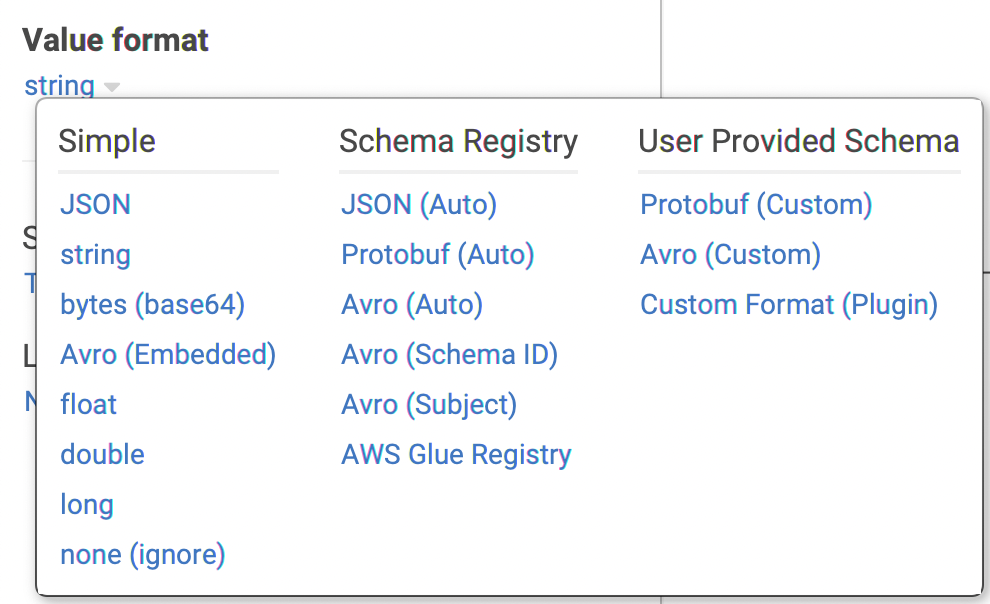
Conduktor automatically pick “Avro (Auto)” when it detects a matching Confluent Schema Registry subject (if configured)
Without Confluent Schema Registry ?
Most Kafka installations rely on the Confluent Schema Registry, that’s the JSON(Auto) , Avro (Auto) and Protobuf (Auto) formats.
When data flow in, Conduktor knows the Avro schema to use because it’s in the payload itself (well, the id only, but that’s enough) if we follow the Confluent’s convention.
But not everyone follows this convention! This means it’s possible that the record does not contain the schema to read the data, and you need to help Conduktor.
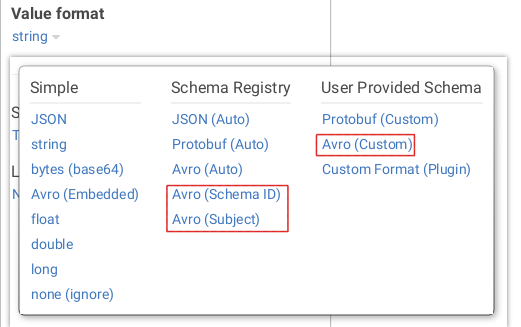
With Avro, you can help Conduktor in 3 ways:
- Which subject to use :
Avro (Subject)(if using Confluent Schema Registry) - Which schemaId to use :
Avro (Schema ID)(if using Confluent Schema Registry) - Which schema to use :
Avro (Custom)(no need to the registry)
- I choose
Avro (Custom)format - I paste my custom schema into the textarea
- I check “Confluent Encoding” because in my case, data are encoded using Confluent’s convention
- In most cases, this will NOT be checked if we’re using this feature
- The data will be read using this schema!
%20(1).png?fit=max&auto=format&n=5TjI4-HLqdnQIYNU&q=85&s=25b00db12b78356d88ee9babe06a1487)
With Protobuf, provide the schema
LikeAvro (Custom) format, theProtobuf (Custom) allows you to paste a raw Protobuf 3 schema to decode messages.
The workflow is the same as Avro :
- I choose
Protobuf (Custom)format - I paste my custom proto3 schema into the textarea
- The data will be read using this schema!
%20(1).png?fit=max&auto=format&n=5TjI4-HLqdnQIYNU&q=85&s=bc80810d054fee37cc7eed0eafaeba49)
Conduktor will iterate over all root message types in the provided schema and select the best one for each message (the first type decoding without missing or unknown fields).
Using AWS Glue Registry
With AWS Glue Registry, the registry name and the schema information (including the format) are embedded in the message. All you need to do is provide the AWS region of your registry.
Possible errors (magic byte)
If you try to consume Avro data without properly configuring it (and because it was not auto-detected by Conduktor for some reasons), you’ll end up with garbage data like this:.png?fit=max&auto=format&n=_zKfCzX656hjdK9R&q=85&s=e9942866cc336444ecb9009cdd23a0bd)
.png?fit=max&auto=format&n=_zKfCzX656hjdK9R&q=85&s=d3c1fa332b99f7846952cc8e30a5a742)