- Alias topics are topics that can be accessed with a name (alias), but point to another, real topic behind the scenes. Alias topics can be very useful when you want to share topics but have sensitive naming conventions; or in scenarios where underlying topics might be frequently renamed.
- Concentrated topics transparently co-locate multiple topics in the same physical topic behind the scenes, acting as pointers to reduce costs on low-volume topics with large partition counts. They are completely transparent to consumers and producers and allow you to emulate different partition counts irrespective of the backing physical topic’s partition count.
- Topic views filter records from physical topics using SQL WHERE clauses. This is the recommended approach for filtering JSON data.
- SQL topics DEPRECATED use SQL language to query and filter an existing topic.
- CEL topics DEPRECATED another way to filter an existing topic using CEL expressions instead of SQL.
Alias topics
Alias topics act as pointers that target a specific physical topic, defined with the AliasTopic resource. One of Kafka’s limitations is that you can’t rename topics - an issue that is solved with alias topics. You can have a number of alias topics pointing to the same physical topic.Use
manages an alias topic mapping in its internal configuration by registering a target physical topic. This topic will be presented to Kafka clients like a regular topic. However, all requests for this topic will be forwarded to the physical topic. This means that consumer groups, fetch and produce are shared. Also, the alias topic does not replace the original one. For example, if you create an alias topicapplicationB_orders that’s pointing to a physical topic orders, a client that can access the physical topic would be able to see both topics.
Limitations
- using delegated Kafka security SASL delegated security protocols aren’t supported.
- Alias topics can’t reference another alias topic.
Concentrated topics
Occasionally, topics have to be created for logical, rather than technical reasons (e.g. to differentiate between business units) which can result in considerable overuse of Kafka resources. Conduktor’s topic concentration allows data from a set of topics to be represented on a single underlying topic. Clients connecting through Conduktor Gateway can use concentrated topics as usual without any additional configuration. For example, let’s say we have the following topics:- us_east_orders - 100 partitions
- us_west_orders - 100 partitions
- emea_orders - 100 partitions
- latam_orders - 100 partitions
- concentrated_orders - 100 partitions
Configuration
Concentrated topics can be configured in two ways:- ConcentrationRule (recommended): YAML configuration with pattern matching and advanced features
- REST API: direct HTTP API calls for manual topic mapping
- ConcentrationRule (YAML)
- REST API
To create concentrated topics, first deploy Then topics that match the ConcentrationRule 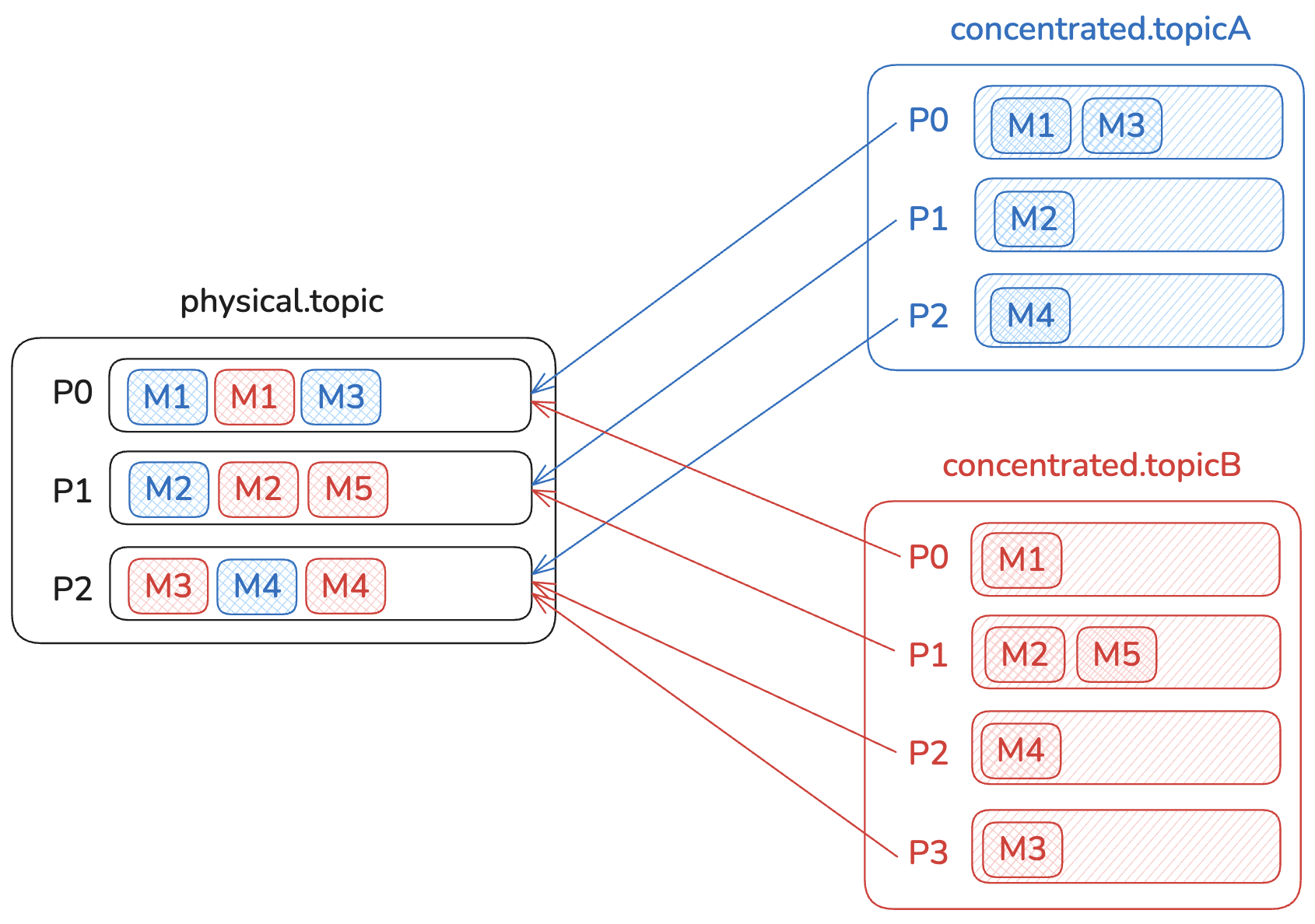
ConcentrationRule:spec.pattern:concentrated.topicA and concentrated.topicB) with partition counts of 3 and 4 respectively, mapped to a single physical topic (physical.topic) with three partitions.To ensure that consumers don’t consume messages from other partitions or from other concentrated topics, we store the concentrated partition and the concentrated topic name in the record headers. Gateway will automatically filter the messages that should be returned to the consumer.Limitations
Consumer offsets
When consuming from a concentrated topic, messages and ordering is always preserved but any metadata calculations (primarily lag and message count) are unlikely to be as expected. This is because the associated metadata is from the backing Kafka topic, rather than the concentrated topic seen from the perspective of the consumer. This is a known limitation.Compact and delete+compact topics
You can create concentrated topics with any cleanup.policy, but yourConcentrationRule has to have a backing topic for each of them, otherwise it won’t let you create the topic.
spec.deleteCompact is commented out, trying to create this topic will fail:
ConcentrationRule. This prevents you from declaring a backing topic with a cleanup.policy of delete on the ConcentrationRule spec.physicalTopic.compact field.
Restricted topic configurations
The following list of topic properties are the only allowed properties for concentrated topics:partitionscleanup.policyretention.msretention.bytesdelete.retention.ms
retention.ms and retention.bytes can be set to values lower or equal to the backing topic. If a user tries to create a topic with a higher value, topic creation will fail with an error:
spec.autoManaged.
Auto-managed backing topics
WhenautoManaged is enabled:
- backing topics are automatically created with the default cluster configuration and partition count.
- concentrated topics created with higher
retention.msandretention.bytesare allowed. This automatically extends the configuration of the backing topic.
Message count, lag and offset (in)correctness
By default, concentrated topic reports the offsets of their backing topics. This impacts the calculations of Lag and Message Count that relies on partition EndOffset and group CommittedOffset.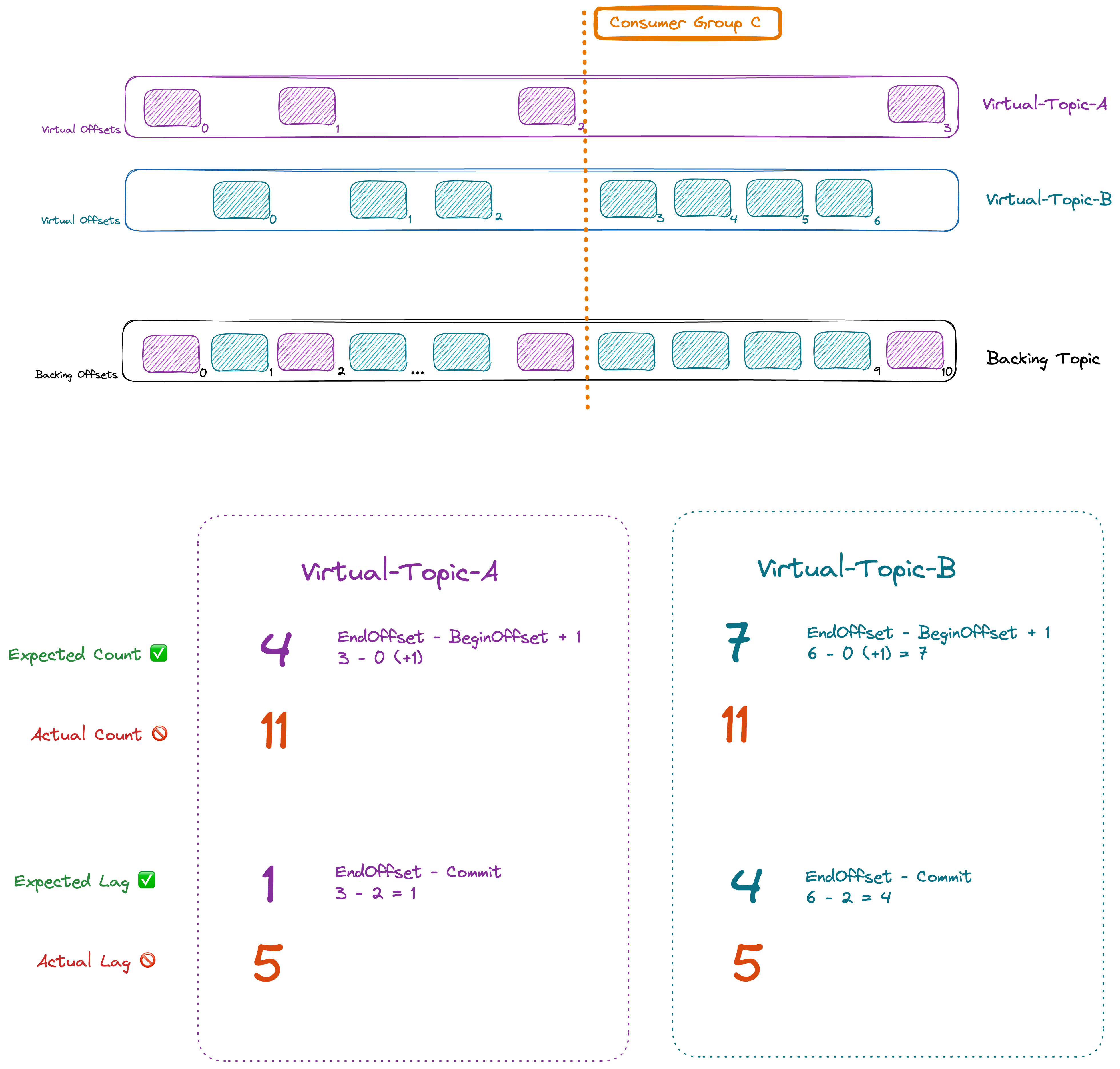
EndOffset of the physical topic. This can create confusion for customers and applications that will see incorrect metrics.
To counter this, we’ve implemented a dedicated offset management capability for ConcentrationRules. Enable virtual offsets by adding the following line to the ConcentrationRule:
spec.offsetCorrectnessonly applies to concentrated topics with thecleanup.policy=deletespec.offsetCorrectnessis not retroactive on previously created concentrated topics
Known issues with offset correctness
There are three known issues with the offset correctness in concentrated topics: 1. Performance On startup, Gateway has to read the concentrated topic entirely before it’s available to consumers. The end-to-end latency is increased by up to 500 ms (orfetch.max.wait.ms, if non-default).
2. Memory
Gateway consumes about ~250MB of heap memory per million records it’s read in concentrated topics. This value is not bound, so we don’t recommend offset correctness on high-volume topics, and recommend to size your JVM accordingly.
3. Unsupported Kafka API
DeleteRecordsis not supported- Transactions are not supported
- Only
IsolationLevel.READ_UNCOMMITTEDis supported (usingIsolationLevel.READ_COMMITTEDis undefined behavior) - Partition truncation (upon
unclean.leader.election=true) may not be detected by consumers
offsetCorrectness enabled, there’s currently a limitation for consumer groups where the data in the topics is slow moving, and/or the consumer groups are not committing their offsets frequently.
If a consumer group with a committed offset waits for the backing physical topic longer than the retention time (without committing a new offset), there’s a possibility for that consumer group to become blocked.
In this scenario, a consumer group whose last committed offset has been removed from the topic, the group becomes blocked only if Gateway restarted before the next offset commit. If this limitation happens, the offsets for the affected consumer group will need to be manually reset for it to continue.
Topic views
Topic views provide non-materialized views of physical Kafka topics, similar to database views. They apply transformations to records as they’re consumed, without modifying the underlying data. Currently, topic views support SQL-based filtering and projection on schema-less JSON. Support for additional transformations (for example, CEL) and data types (for example, schema-based JSON and Avro) is planned. Topic views are configured as a dedicated Gateway resource, similar to alias topics.Topic views are a replacement for SQL topics and CEL topics, which are deprecated. Topic views will be extended to cover all of their functionality, after which the plugins will be removed.
Prefer a hands-on walkthrough? Migrate a Kafka Streams transformer to a Topic View runs the whole before → after migration — creating the view, seeding offsets, and cutting a downstream consumer over with no reprocessing.
How it works
When a consumer fetches from a topic view, Gateway:- Reads records from the underlying physical topic
- Applies the configured transformation to filter or modify each record
- Returns the resulting records to the consumer
__consumer_offsets. This means you may see gaps in offset numbers when records are filtered out. The committed offset is always the offset of the last record in the batch, regardless of whether that record was filtered out.
Topic views are read-only by design, but Gateway doesn’t enforce this yet. Producing to a topic view isn’t blocked, so avoid it until enforcement is added.
Configuration
Configure topic views using the Gateway REST API or Conduktor CLI. For all available fields, see the TopicView resource reference.- curl
- Conduktor CLI
SQL transformation
When usingtransformation.type: sql, topic views filter and transform records using SQL syntax. The transformation uses a subset of SQL that will be extended in future releases.
Topic names with dash
- characters have to be double quoted, as the dash is not a valid character for a SQL name. For example, if you have a topic our-orders, use SELECT * FROM "our-orders" WHERE ...Projection
Use theSELECT clause to reshape records by renaming fields, selecting a subset of fields, computing new values, or including record metadata.
Supported predicates
=,>,>=,<,<=,<>(standard comparison operators)REGEXP(regular expression matching)ANDoperator for combining multiple conditions (ORis not yet supported)
Regular expression matching
UseREGEXP for pattern matching. SQL LIKE is not supported, so use REGEXP in place of LIKE wildcards:
Date and time values
A record’s date and time values are typically stored as strings, since JSON has no native date or time type. To compare them chronologically rather than lexically, write the comparison value as a JDBC escape literal so Gateway reads it as a date or time:- Date:
{d 'YYYY-MM-DD'} - Time:
{t 'HH:MM:SS'} - Timestamp:
{ts 'YYYY-MM-DD HH:MM:SS'}
Use the JDBC escape form for date and time comparisons. Two alternatives don’t work:
- A plain string literal (such as
event_at > '2026-01-01 12:34:56') is compared lexicographically, not chronologically. Gateway doesn’t error, but range results can be wrong across mixed formats. - The ANSI SQL forms
DATE '2026-01-01'andTIMESTAMP '2026-01-01 12:34:56'aren’t supported.
Nested field access
Access nested JSON fields using dot notation:Array index access
Access array elements using bracket notation with backticks:Backticks are required around field names with array index notation.
Record key, headers, and Kafka metadata
In addition to record value fields, you can reference the record key, headers, and Kafka metadata:record.timestamp is milliseconds since the epoch. Header names that contain . aren’t supported in this syntax.Virtual Cluster topic names
If you use Virtual Clusters, the topic name in theFROM clause has to be the full physical name on the backing cluster, including the Virtual Cluster prefix. This applies even when the topic view targets a topic in the same Virtual Cluster.
For example, a topic view in the vc-alice Virtual Cluster that targets the orders topic in that cluster reads from the physical name vc-aliceorders:
Unsupported syntax
Topic views support only the SQL features documented above. The following are examples of popular features that are not yet supported: Operators:ORoperator (planned)INoperatorLIKEwith wildcardsBETWEENIS NULL/IS NOT NULL- String concatenation (
||) - Numerical operators (
+,-,*,/etc)
- String functions (
UPPER,LOWER,CONCAT) COALESCE
JOIN- Subqueries
- path expressions returning an array or an object
- Array wildcards:
items[*].nameoritems.*.name - JSONPath filter expressions:
items[?(@.price > 10)] - Slices (
items[0:2]), index lists (items[0,1]), and recursive descent (..status)
Error handling
Thespec.onError field declares what Gateway should do when a record can’t be transformed (for example, the SQL doesn’t match the record structure). The field is required on every topic view and takes one of two values:
DROP— drop the failing record from the response and continue.FAIL_FETCH— fail the fetch for that partition.
Set the consumer group ID
To consume from a topic view, include the view’s name in your consumer’sgroup.id, delimited by ::. The rest of the group.id is free-form, so you can keep your usual naming alongside the view name.
group.id has to have a different backing topic. You can’t name two views of the same backing topic in the same group.id.
This keeps consumers of different views in separate Kafka consumer groups. Without it, Kafka can split a backing topic’s partitions across views in the same group, and each consumer drops the records meant for the other, causing silent data loss.
Gateway checks the group.id when a consumer joins a group or commits offsets, and rejects it with an INVALID_GROUP_ID error if it doesn’t follow this convention. The check also covers a topic view’s backing topic, whether read directly or through an alias, since that’s equivalent to reading the view. Concentrated topics are exempt, and a consumer that touches no topic view or backing topic is unaffected.
Requiring a specific
group.id format is a temporary limitation. We plan to remove it in a future release, once Gateway supports the KIP-848 consumer group protocol.Planned features
Topic views currently apply SQL transformations to schema-less JSON. We plan to add:- More transformation types: CEL (Common Expression Language) and RSQL, alongside SQL.
- Schema Registry support: filtering and projection on Avro and Protobuf values, in addition to schema-less JSON.
JSON_OBJECTinSELECT: construct complex, nested JSON output in projections over schema-less data.
SQL topics
Conduktor Gateway’s SQL topic feature uses a SQL-like language to filter and project messages, based on a simple SQL statement:FetchResponse only (i.e., resulting topic is read-only):
SELECT [list of fields] FROM [topic name] WHERE [field filter criteria]
Topic names with dash
- characters have to be double quoted, as the dash is not a valid character for a SQL name. For example, if you have a topic our-orders, use SELECT * FROM "our-orders" WHERE ...- With filter records based on more than one condition, only
ANDoperator is supported - Supported predicates:
=,>,>=,<,<=,<>andREGEXP(RegExp MySQL Operator) - Case expression is supported
- Filtered by:
- Record key (It supports SR):
- Record key as string: -
.. WHERE record.key = 'some thing' - Record key as schema:
.. WHERE record.key.someValue.someChildValue = 'some thing'
- Record key as string: -
- Record value (It supports SR):
.. WHERE $.someValue.someChildValue = 'some thing' - Partition:
.. WHERE record.partition = 1 - Timestamp:
.. WHERE record.timestamp = 98717823712 - Header:
.. WHERE record.header.someHeaderKey = 'some thing' - Offset:
.. WHERE record.offset = 1
- Record key (It supports SR):
Schemas and projections
If your data uses a schema, then it’s not possible to make use of the projection feature here because the resulting data will no longer match the original schema. For plain JSON topics, you can use theSELECT clause to alter the shape of the data returned; however, for schema’d data (Avro and Protobuf) you must not use a projection, i.e. the select should be in the form:
SELECT * FROM ...
Filtering with the where clause is still supported.
Configuration
Example
Schema registry with secured template
- curl
- Conduktor CLI
Filter topics with CEL
Conduktor Gateway’s CEL topic feature uses CEL (Common Expression Language) expression to filter messages, based on a simple CEL expression in the form. Currently- Filtered by:
- Record key (It supports SR):
- Record key as string: -
.. record.key == 'some thing' - Record key as schema:
.. record.key.someValue.someChildValue == 'some thing'
- Record key as string: -
- Record value (It supports SR):
.. record.value.someValue.someChildValue == 'some thing' - Partition:
.. record.partition == 1 - Timestamp:
.. record.timestamp == 98717823712 - Header:
.. record.header.someHeaderKey == 'some thing' - Offset:
.. record.offset == 1
- Record key (It supports SR):
Configuration
Example
Schema registry with secured template
- curl
- Conduktor CLI
Schema registry configuration
If you don’t supply a
basicCredentials section for the AWS Glue schema registry, the client used to connect will attempt to find the connection information from the environment. The required credentials can be passed to Gateway in this way as part of core configuration.
Find out more about credentials from AWS documentation .
Read our blog about schema registry .