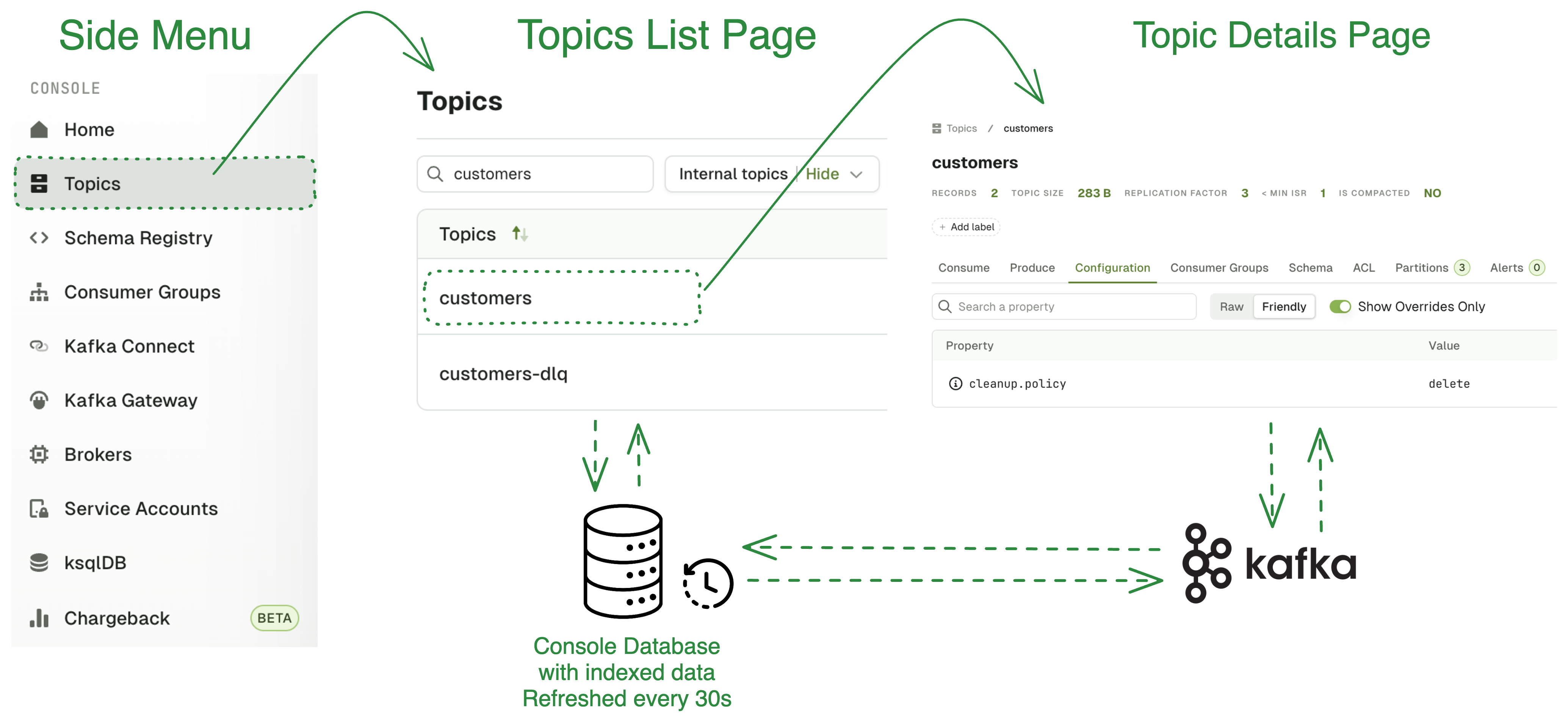
Detail pages are not using Indexing. As soon as you’re on a page for a specific topic or consumer group, the data is fetched directly from the Kafka cluster.
Benefits
Indexing improves user experience and provides functionality that’s not available with out-of-the-box Kafka resources, such as:- smart tables with sorting and filtering capabilities, allowing you to get message count, size and much more
- search and labelling that allows you to organize and find required resources
Examples
These are just some examples of how Indexing can help you:- identify idle topics: which topics (that have no active consumers and producers) haven’t published data for more than a week?
- are there any over-partitioned topics - topics that have a large number of partitions while the biggest consumer group only has a few members consuming in parallel?
- prioritize data at risk topics: which topics are at risk of losing data, because of the replication factor or the min ISR being incorrect?
- find outliers topics: which topics contain bad or overridden configurations that they shouldn’t have?
- remove over-replicated applications: which consumer groups have idle members? Typically, this is because the number of consumers exceeded the number of total partitions.
Circuit breaker configuration
Each indexed task in Console includes configurable circuit breaker behavior that provides fine-grained control over indexing resilience and recovery. This configuration helps prevent prolonged indexing outages and gives administrators better control over system behavior.Configuration parameters
sequentialFailureThreshold
- Controls how many consecutive failures have to occur before the circuit breaker activates
- When the threshold is reached, the indexing task will temporarily stop attempting to collect data
- Prevents resource exhaustion during extended connectivity or permissions issues
blockingDuration
- Defines how long the circuit breaker remains active before attempting to resume indexing
- Provides a controlled recovery mechanism with predictable timing
- Ensures predictable recovery intervals for indexing operations
Benefits
With these circuit breaker settings, you can:- Adjust failure detection sensitivity based on your environment’s reliability
- Control recovery timing to balance system stability with data freshness
- Maintain predictable indexing behavior even during temporary infrastructure issues
- Prevent resource exhaustion during extended connectivity problems
Circuit breaker configuration is applied per indexed tasks (e.g., topic metadata polling, consumer group indexing). For guidance on optimal settings for your specific deployment scenario, contact support .
Troubleshoot
I've just created a topic, but get 'Indexing in progress'/can't see the metadata
I've just created a topic, but get 'Indexing in progress'/can't see the metadata
Topics created ‘now’ would not be indexed until the next Indexing cycle.This means they wouldn’t appear in Console for up to 30 seconds.To mitigate this, we’ve come up with a counter-measure: any user request to the topic list will ALWAYS make one AdminClient call to Kafka:
listTopics.It’s cheap, simple and will only return the topic names. So, when topics are listed in Console, 99% of the time Indexing will serve all the topics with all the columns (name, partitions, count, size, etc.) and 1% of the time Indexing will serve most topics except for one or two not-indexed yet where only the name will be available.