- Get notified about new releases! Click the RSS feed button above.
- Try out the latest Conduktor version for free.
- Have questions or feedback? Get in touch .
Updated features
Configurable HTTP request timeout
The Console HTTP request timeout is now configurable through the newCDK_PLATFORM_HTTP_REQUESTTIMEOUTSECONDS environment variable (property: platform.http.requestTimeoutSeconds). Increase the timeout to accommodate long-running requests behind slow upstream systems, or lower it to fail faster in environments with tight service-level objectives.Faster ApplicationInstance applies on Confluent clusters using role bindings
For Confluent Cloud and Confluent Platform clusters configured to use role bindings (rather than ACL mode), applying an ApplicationInstance now skips role binding API calls when the ApplicationInstance has no state change, and issues the remaining calls in parallel. This cuts apply time on unchanged instances and speeds up applies that do have work to do.Fixes
- Improved performance of the ApplicationGroup API.
- Improved transactionality and rollback behavior of the ApplicationGroup API.
Updated features
Configurable HTTP request timeout
The Console HTTP request timeout is now configurable through the newCDK_PLATFORM_HTTP_REQUESTTIMEOUTSECONDS environment variable (property: platform.http.requestTimeoutSeconds). Increase the timeout to accommodate long-running requests behind slow upstream systems, or lower it to fail faster in environments with tight service-level objectives.Faster ApplicationInstance applies on Confluent clusters using role bindings
For Confluent Cloud and Confluent Platform clusters configured to use role bindings (rather than ACL mode), applying an ApplicationInstance now skips role binding API calls when the ApplicationInstance has no state change, and issues the remaining calls in parallel. This cuts apply time on unchanged instances and speeds up applies that do have work to do.Preview features
RBAC on labels
Early access to role-based access control (RBAC) on labels is available in this release. Contact your Conduktor account team if you’d like to try it. Full documentation will be published with the v1.47.0 release.Fixes
- Fixed a regression in group membership reconciliation during single sign-on (SSO) login that affected some SSO providers.
- Improved performance of the ApplicationGroup API.
- Improved transactionality and rollback behavior of the ApplicationGroup API.
Security advisories
Console v1.46.1 is flagged by image scanners (Trivy, Grype) for CVE-2026-54512 and CVE-2026-54513 againstcom.fasterxml.jackson.core:jackson-databind. Both findings have no practical impact on Console.Console’s own jackson-databind is already patched (2.21.4 and 3.2.0). The flagged 2.15.2 version comes from a copy of jackson-databind that is shaded and relocated inside a graph library Console uses internally to support stream lineage. Its classes are not on the classpath as com.fasterxml.jackson.databind.*, so the vulnerable code paths can’t be reached from Console. The library uses its shaded copy for internal serialization, not for deserializing attacker-controlled input.We intend to address this finding in the next major Console release.New and updated features
Stream lineage
Stream lineage gives you an interactive map of how data flows across your Kafka estate, with the topics, applications, and service accounts that produce or consume each stream rendered side by side. Use it to trace how a topic is being read and written across applications, identify which service accounts depend on a given topic, and investigate the downstream impact of a topic or application change.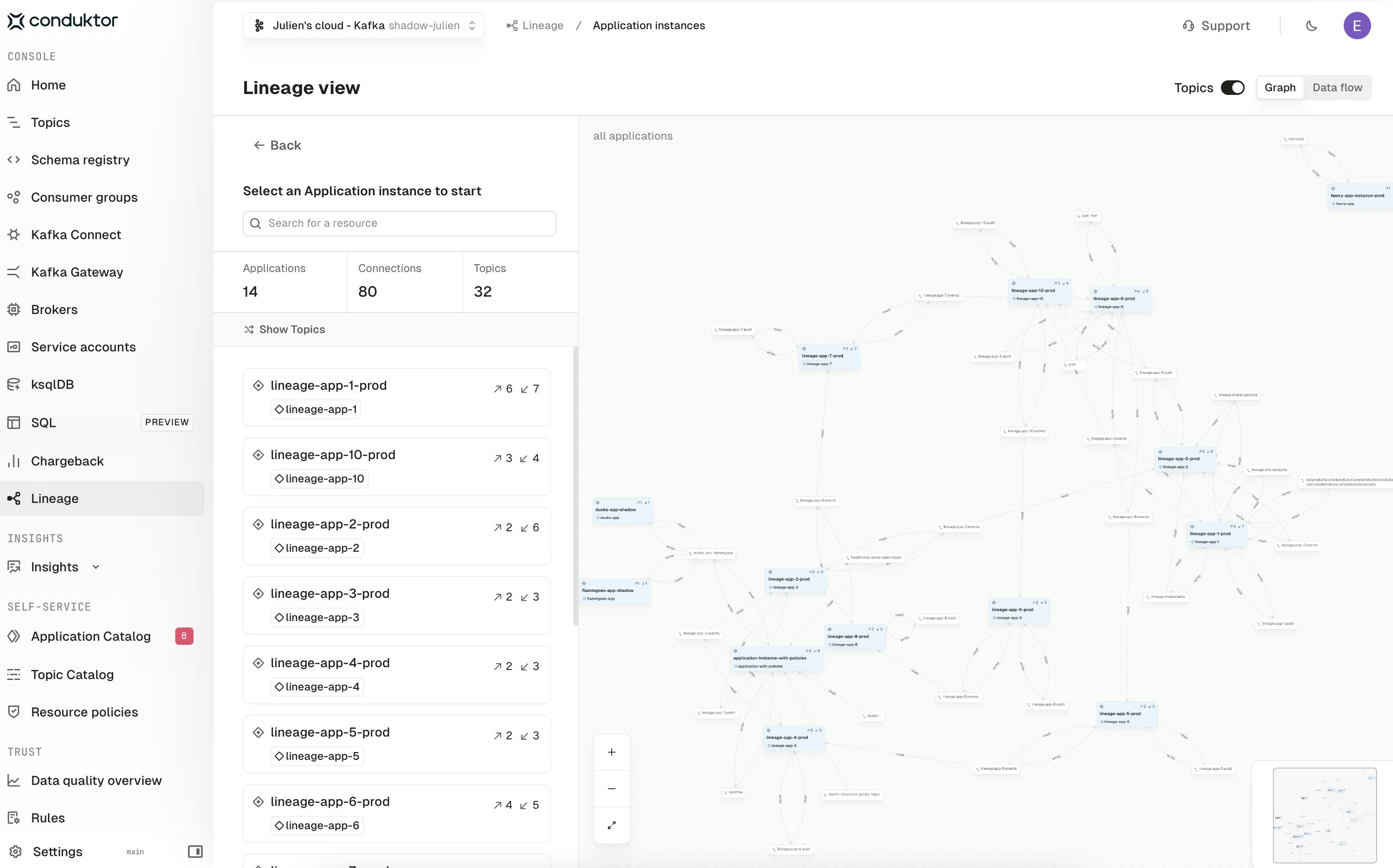
ApplicationInstance and ApplicationInstancePermission resources — so it stays in sync with the model you’ve declared in Console. On Confluent Cloud and Confluent Platform clusters configured to use role bindings, the edges are populated from those role bindings instead.Stream lineage offers two ways to explore your platform:- Application instance view — see how Self-service applications connect through the topics they share, with a Topics toggle to either include the topics on the graph or collapse them into a compressed application-to-application view
- Service account view — reason about access at the Kafka authorization layer, with each service account as a node and edges drawn straight from the ACLs that grant read or write access to a topic
CDK_STREAM_LINEAGE_* environment variables to tune the in-memory graph cache.Kafka Connect lifecycle and offsets
- You can now stop a Kafka Connect connector. Stopping a connector releases its tasks and resources, unlike pausing, which keeps them assigned. Manage the new
STOPPEDstate from the connector page or the public API. - The connector page has a new Offsets tab to view a connector’s source and sink offsets. To edit or reset offsets, use the public API while the connector is stopped to control where it resumes from.
- You can set the initial state of a connector when you create it. Set
initialStatetoRUNNING,PAUSED, orSTOPPEDto deploy a connector without immediately starting it.
Consumer group protocol reporting
Consumer group descriptions now report the group type and protocol (CLASSIC or CONSUMER) introduced by the next-generation consumer group protocol (KIP-848), so you can tell at a glance which clients have moved to the new protocol.Mask all fields in a data masking policy
Data masking policies now have a Mask all fields toggle. When enabled, Console applies the policy’s masking rule to every scalar value it finds in a message — at every nesting depth, including inside arrays — without you needing to enumerate field paths. Numbers are masked to0 and booleans to false so message schemas stay valid; per-field policies that target specific paths still take precedence.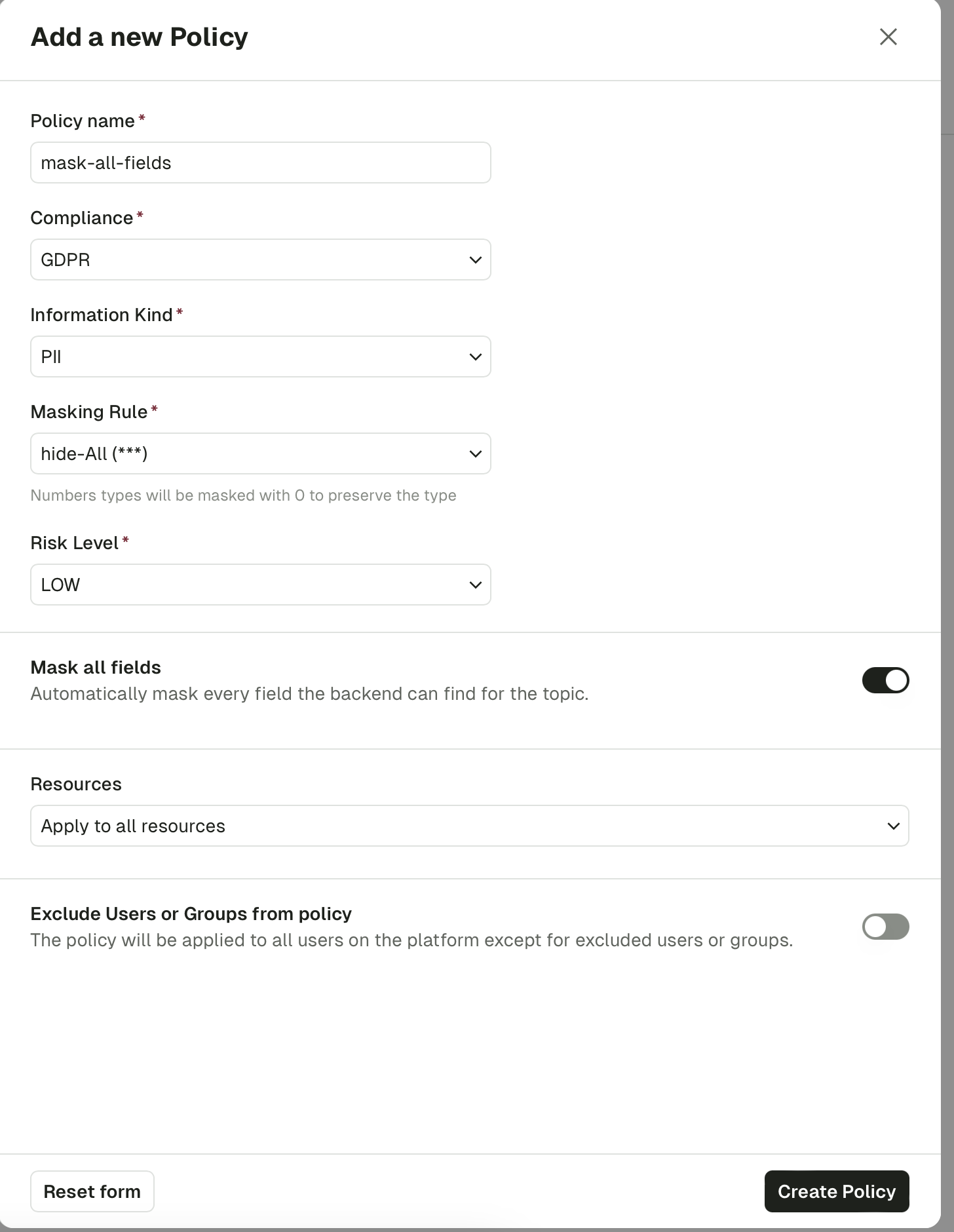
Permission management
-
Topic owners can now be given access to view the ACLs on their owned topics without needing a cluster-wide permission. To view topic ACLs, a user has to be granted one of:
clusterViewACLon the related cluster (classic RBAC), which continues to cascade ACL viewing to every topic in the cluster, or- one of the Self-service application instance permissions
applicationInstancePermissionGrantAccessorapplicationInstancePermissionProposeAccess, assigned through an application group on the owningApplicationInstance.
- Three new Kafka Connect permissions let you grant connector stop and offset operations independently of pause, resume, and restart: stop a connector, view offsets, and manage offsets. These default to off for existing custom roles, so existing permission grants are unchanged until you opt in.
Resource templates
Platform teams can now define topic and connector templates that pre-fill the Console creation forms. Admins curate templates with the CLI — set a display name, an optional description, and the default partitions, replication factor, configuration and labels — and application teams pick one to start from a vetted setup instead of a blank form, adjusting the values before they submit. Templates can include{{placeholder}} values, such as a team name in a topic naming convention, that the user replaces during creation. Templates are suggestions, not rules: pair them with a ResourcePolicy to enforce the boundaries.See the TopicTemplate and ConnectorTemplate reference for the YAML schema.Chargeback
- Chargeback is now enabled by default. The
CDK_CHARGEBACKV2_ENABLEDenvironment variable defaults totrue; set it tofalseto disable Chargeback. - Chargeback now attributes Kafka Connect costs. Set a default connector task hour cost per cluster, with optional per-connector-class overrides, then view Connect costs in the cluster, application, and label views and drill down into individual connectors.
- Connectors that carry a Chargeback Label can now be grouped and filtered in the Chargeback label view.
- The Chargeback CSV export now includes connector task hours and connect cost columns.
- The Chargeback public API now exposes endpoints to manage cost rates and Chargeback Labels, and to export Chargeback data as CSV.
Public API changes
- The public API now exposes connector lifecycle operations: stop, pause, resume, restart, and offset management (view, edit, reset).
- The public API now exposes consumer group operations: describe a group, view its members and topics, delete a group, and preview or reset offsets.
- The Chargeback public API now exposes endpoints to manage cost rates and Chargeback Labels, and to export Chargeback data as CSV. See the Chargeback section for the full set of related changes.
Quality of life improvements
- Export includes Kafka headers
Fixes
- Consumer offset retrieval no longer fails when some partition leaders are offline
- Consumer page date-time filters now display time in local time instead of UTC
- SSO test for Azure Entra ID shows explanation why group or email claims are missing
- Added
CORTEX_COMPACTOR_RETENTION_PERIODenvironment variable - Support nested OIDC group claim
- Breaking changes
- New and updated features
- Preview features
- Deprecated features
- Quality of life improvements
- Fixes
- Security advisories
Breaking changes
Mixed network configuration
Gateway now refuses to start if you mix legacy network configuration variables with listener configuration variables. Previously, the legacy variables were silently ignored in that case. See Migrate to listener configuration for a side-by-side mapping and a worked example.Internal Kafka client upgraded to 4.2
Gateway now uses the Apache Kafka client 4.2 internally, upgraded from 3.9. This drops support for the oldest client protocol versions, so applications connecting to Gateway need a Kafka client of at least Apache Kafka 2.1 for the Java client, or the equivalent for other libraries (see KIP-896). Only clients older than that are affected. It does not change the minimum Kafka broker version that Gateway supports. We expect low impact for most deployments.Gateway does not yet support the new Kafka 4 group protocols and now blocks them for every client, in both API blocking modes:
- Share groups (KIP-932), also known as Kafka queues.
- Streams groups (KIP-1071), the new Kafka Streams rebalance protocol.
GATEWAY_FEATURE_FLAGS_BLOCK_UNSUPPORTED_APIS=false, Gateway passed the KIP-932 share-group APIs through to the backing Kafka cluster. They’re now always blocked. See API blocking modes.New and updated features
New listener configuration GA
The new configuration format supporting multiple listeners withGATEWAY_LISTENER_<NAME>_* environment variables is now generally available. It graduates from preview to the recommended way to configure Gateway networking.The same configuration can define one or many listeners. Each listener has its own security protocol, routing strategy and network bindings, letting you expose Gateway through multiple endpoints (for example, internal PLAINTEXT and external SASL_SSL) when needed.With listener configuration, GATEWAY_SECURITY_MODE and GATEWAY_ACL_ENABLED have to be set explicitly — they’re no longer inferred from the backing Kafka cluster.See Configure Gateway listeners.Topic views GA
Topic views graduate from tech preview to general availability and are now enabled by default. They provide non-materialized, SQL-filtered views of physical Kafka topics.Building on the 3.19.0 preview, topic views now also support:- Consumer
group.idvalidation to prevent the silent data loss that can occur when a consumer group is shared across views of the same backing topic. See Set the consumer group ID. - Expanded SQL: date and time comparisons, record metadata in the
SELECTclause, and parse-time rejection of unsupported multi-value field paths. See SQL transformation. onErrorenforced at fetch time, includingFAIL_FETCH. See Error handling.
Faster ACL authorization
ACL evaluation is now more efficient, especially on clusters with many ACLs. Authorization decisions are unchanged.Preview features
Incremental fetch sessions
Gateway can now support Apache Kafka incremental fetch sessions (KIP-227) on the Fetch API, behind a feature flag. Incremental fetch sessions let a consumer send only the partitions that changed after it opens a session, which lowers Fetch request overhead for consumers that read from many partitions.Enable it withGATEWAY_FEATURE_FLAGS_INCREMENTAL_FETCH_SESSIONS_ENABLED=true. You can’t combine it with topic ID support. See incremental fetch sessions for setup and limitations.Deprecated features
Legacy network configuration
Deprecated in:v3.20.0. Removal planned for v3.23.The global GATEWAY_PORT_*, GATEWAY_ADVERTISED_HOST, GATEWAY_HOST, GATEWAY_ROUTING_MECHANISM, GATEWAY_BIND_HOST, GATEWAY_ADVERTISED_SNI_PORT, GATEWAY_ADVERTISED_HOST_PREFIX, GATEWAY_SNI_HOST_SEPARATOR and GATEWAY_SECURITY_PROTOCOL environment variables are deprecated. New deployments should use listener configuration.Existing deployments continue to work without changes, but Gateway now logs a deprecation warning at startup when it detects any of these variables, pointing to the migration guide.When you’re ready to migrate, see Migrate to listener configuration for a side-by-side mapping and a worked example.Quality of life improvements
Upgrade to JDK 25
Conduktor Gateway now runs on JDK 25, replacing JDK 21. Both are long-term support (LTS) releases. This is a runtime and toolchain change only — Gateway features and configuration are unchanged — and it is low impact for most deployments. The runtime base image moves fromeclipse-temurin:21-jdk to eclipse-temurin:25-jdk.If you build your own image FROM the Gateway image, or set custom JVM options, verify any custom JAVA_OPTS against the JVM options removed or obsoleted across JDK 22–25: an unrecognized flag prevents the JVM from starting.Automatic OAuth URL allow-list
The Kafka 4 client library adds a security control: theorg.apache.kafka.sasl.oauthbearer.allowed.urls system property. The OAuth or OpenID Connect (OIDC) client only calls a URL that’s on this allow-list and refuses any URL that isn’t. Now that Gateway’s internal Kafka client is on 4.2, this property applies to Gateway too.Gateway sets the property automatically at startup from the OAuth URLs you already configure: the downstream JSON Web Key Set (JWKS) endpoint and any upstream token endpoints. OAuth authentication continues to work after the upgrade with no extra JVM argument.To control the allow-list yourself, for example to add or restrict URLs, you can still set the property manually, which overrides the value Gateway derives.Fixes
- Include async-profiler to help investigating performance issue
- Secret env vars whose values start with a YAML-special character (such as
[) no longer cause Gateway to fail at startup. Affected vars:GATEWAY_SSL_KEY_STORE_PASSWORD,GATEWAY_SSL_KEY_PASSWORD,GATEWAY_SSL_TRUST_STORE_PASSWORD,GATEWAY_HTTPS_KEY_STORE_PASSWORD,GATEWAY_HTTPS_TRUST_STORE_PASSWORD,GATEWAY_CONFLUENT_CLOUD_API_SECRET,GATEWAY_USER_POOL_SECRET_KEY. - Fix process hang when startup or shutdown fails
- Prevent reprocessing of deleted interceptor configuration on startup
Security advisories
Gateway v3.20.0 is affected by CVE-2026-45799. We will address it in a future release once our upstream dependencies allow.Fixes v1.44.2
- Fixed erroneous “subject not found” errors appearing in the topic record detail view when the subject exists.
CVEs in conduktor-console-cortex
Three CVEs are flagged as high severity in the Cortex container image:- CVE-2026-34040
- CVE-2026-41567
- CVE-2026-42306
CVE-2026-34040
This exploit involves an AuthZ plugin bypass in the Docker daemon HTTP API middleware. Cortex doesn’t embed or run dockerd, so it isn’t affected.CVE-2026-41567 and CVE-2026-42306
Both CVEs relate to thedocker cp command and its implementation in dockerd. Cortex doesn’t embed or run dockerd, so it isn’t affected.New features
Gateway Community Edition
Conduktor Gateway introduces a new edition: Gateway Community Edition — a Kafka-managed passthrough proxy with no Gateway-managed features. Standard Conduktor Gateway licenses are unaffected by this release.See Gateway Community Edition for included capabilities, excluded features, customer-visible restrictions, and how to obtain a license.Security advisories
This release resolves CVE-2026-22016 (Java API for XML Processing) and CVE-2026-34282 (Networking), both flagged in Gateway v3.19.0.Fixes
- Fixed an issue where Chargeback did not attribute costs to applications managed through Self-service in the service accounts panel.
- Fixed a Chargeback issue where costs could be assigned to the wrong day for users in non-UTC timezones.
Security advisories
- Updated the JDK 21 base image to include upstream patches for CVE-2026-34282.
- Updated the bundled Netty dependency to address recently disclosed CVEs.
Breaking changes
Self-service owner group permissions
Starting with Console 1.45.0, application owner groups no longer have implicit permissions to create API keys, request or grant access, or manage resources at the application instance level. Owner groups can now only create ApplicationGroups.All previous owner group permissions have to be explicitly assigned through ApplicationGroups using the newinstancePermissions field.You’re impacted if
You rely on application owner group members to:- Create or delete application instance API keys
- Request access to other teams’ topics through the Topic Catalog
- Grant or approve access requests to your application’s topics
- Manage service accounts for the application instance
Do you have to do anything?
In most cases, no. On upgrade to Console 1.45.0, an automatic migration creates a mirror ApplicationGroup for each existing application owner group. This mirror group is assigned all instance permissions (applicationInstancePermissionRequestAccess, applicationInstancePermissionGrantAccess, applicationInstancePermissionProposeAccess, applicationInstanceApiKeyManage, serviceAccountManage) so that existing users keep their current access.The mirror group is labeled for identification with the following conventions:- the name is the same as the application name with
-ownerssuffix (e.g. the applicationmy-appwill have a mirror group namedmy-app-owners) - the description starts with
[Default Owner]You can review and adjust these groups after upgrade to restrict specific permissions to specific teams.
instancePermissions field where needed. See the Self-service resource reference for the updated schema.The automatic migration only applies to applications that exist at upgrade time. For new applications created after upgrading, the platform team or application owner has to create an ApplicationGroup with the appropriate
instancePermissions as a first step, otherwise the team will not be able to request or grant access, create API keys, or manage service accounts.Conduktor Console Cortex upgrade
Console 1.45.0 upgrades the bundled Cortex image from 1.18 to 1.21, which includes an upgrade from Prometheus 2.54 to 3.8. This is a one-way upgrade — you cannot roll back to the previous image once data has been written by the new one.You’re impacted if
All deployments running Conduktor Console Cortex are impacted.Pre-upgrade checklist
- Back up TSDB storage. Snapshot your TSDB volume or object storage bucket. This is mandatory — there is no in-place downgrade path.
- Review custom Grafana dashboards. The provided Conduktor Grafana dashboard works without changes, but custom dashboards may need updates due to the PromQL and label changes listed below.
PromQL and query behavior changes
These changes can silently alter query results in custom dashboards, recording rules and alerts:Scraping and ingestion changes
- Targets that don’t return a valid
Content-Typeheader now fail the scrape instead of falling back to the Prometheus text format. If you see scrape failures after upgrading, setfallback_scrape_protocolin your scrape configuration. - UTF-8 metric and label names are now accepted by default. To keep strict pre-upgrade behavior, set
metric_name_validation_scheme: legacy. - Prometheus 3 no longer supports Alertmanager’s v1 API. If your Alertmanager configuration uses
api_version: v1, update to v2 (requires Alertmanager 0.16.0 or later).
Configuration flag changes
The following feature flags have been removed and are now default behavior. Passing them with--enable-feature produces a warning but has no effect:promql-at-modifier, promql-negative-offset, new-service-discovery-manager, expand-external-labels, no-default-scrape-port, agent, remote-write-receiver, auto-gomemlimit, auto-gomaxprocsOf these, no-default-scrape-port may change metric label values — targets like https://example.com/metrics no longer have :443 appended.Other flag changes:remote_writeenable_http2now defaults tofalse. If you depend on HTTP/2 multiplexing for remote write, opt in explicitly.- The log format changed from
go-kit/logtoslog. Anything parsing Cortex logs (for example, Loki recording rules or log-based alerts) needs adjustment.
Cortex-specific changes
- The bucket index is now enabled by default. Disabling it (
-blocks-storage.bucket-store.bucket-index.enabled=false) is not recommended for production. - Ruler API and Alertmanager API flags have graduated from experimental (for example,
-experimental.ruler.enable-apiis now-ruler.enable-api). The old flags still work but are deprecated. - The
-distributor.otlp.enable-type-and-unit-labelsflag is deprecated and replaced by-distributor.enable-type-and-unit-labels. Update your configuration if you use OTLP ingestion.
Disk usage on Kubernetes
In Cortex 1.21, the compactor and cleanup jobs run in parallel rather than sequentially. On large Consoles with significant metric volume, this can cause peak local disk usage to grow enough to fill the pod’s ephemeral storage and trigger eviction.For Kubernetes deployments running large workloads, we recommend attaching a persistent volume to the Cortex pod instead of relying on ephemeral storage, so the compactor has headroom to run alongside cleanup. See Store platform data into a persistent volume in our Helm chart docs for configuration details.New and updated features
Self-service
Granular instance permissions for ApplicationGroups
ApplicationGroups now support a newinstancePermissions field, separate from the existing resource-level permissions field. This lets platform teams delegate application-instance-level actions to specific groups rather than granting them implicitly to all owner group members.Service account management delegation
The newserviceAccountManage instance permission allows platform teams to delegate service account management to specific ApplicationGroups. Previously, service account management was only available to owner group members.UI updates for ApplicationGroup members
The Console UI now checks ApplicationGroup instance permissions when determining access to Self-service actions. ApplicationGroup members with theapplicationInstancePermissionRequestAccess permission can request topic access, and members with applicationInstancePermissionGrantAccess can approve or grant requests directly from the Topic Catalog and Application Catalog pages.Enforce restrictions on ApplicationGroups with a ResourcePolicy
After the migration, application teams own their ApplicationGroups and choose whichpermissions and instancePermissions to assign. Platform teams can keep guardrails on what teams are allowed to grant themselves with a ResourcePolicy of targetKind: ApplicationGroup, linked through spec.policyRef.For example, to enforce GitOps-only approval, restrict ApplicationGroups to a read-only resource permission set and to safe instance permissions — any write operation (topicDelete, topicEditConfig, applicationInstancePermissionGrantAccess, serviceAccountManage) then has to go through the CLI:Unified Chargeback
Chargeback now measures four cost axes — storage, partitions, ingress and egress — across vanilla Kafka, Confluent Cloud and Gateway clusters from a single page:- Three views: group costs by Cluster, Application (with drill-down into application instances) or by the values of a configured label key
- Drill-downs: every row can be expanded to show the topics and service accounts that contributed to its cost
- Chargeback Labels: administrators select which label keys are eligible for grouping (for example,
team,cost-center,env) - Settings drawer: cost rates and Chargeback Labels are managed from a single drawer behind the cog icon, replacing the previous gear flow
- CSV export: the Export dropdown downloads the current view honoring the active filters, view, period and search
AWS Glue schema IaC
Application teams can now manage their Glue schema resources lifecycle through IaC with the addition of the GlueSchema object.Confluent Platform role bindings
Console now supports Confluent Platform Role-Based Access Control (RBAC) role bindings for Self-service. To enable role bindings, go to the Confluent Platform cluster’s provider settings and turn on the role bindings flag.Once enabled, applying a Self-service resource creates Confluent Platform role bindings for the service account instead of Kafka ACLs. Role bindings are also visible in the service account UI for Confluent Platform clusters that have the flag enabled.See the Self-service resource reference for the role bindings created for each resource type, and the Confluent Platform RBAC migration tutorial for step-by-step setup.Subject ACLs for Schema Registry Proxy
Subject ACLs can now be created on application-managed service accounts to control access to specific subjects via the Schema Registry Proxy. This isn’t available on standard ServiceAccount resources, and only takes effect when the service account’s application instance is on a cluster whose Schema Registry is fronted by a Schema Registry Proxy.This provides more granular access control for teams using the Schema Registry Proxy to manage their schemas.Schema Registry Proxy is a preview feature — reach out to your solutions architect for more information.
Fixes
- Added PersonalApiKey audit log type to differentiate from AdminApiKey
- Fixed an error when parsing the Create Connector API response in Kafka Connect 4.2.0+
- Added a detailed cause to deserialization error messages when consuming records
- Fixed a spurious “Subject not found” popup on the record detail view for topics using a Confluent Schema Registry, when deserialization had already succeeded
- Fixed Schema Registry Proxy not syncing subject ACLs to the
_conduktor_srp_commandscommand topic - Fixed the Schema Registry selection on a cluster reverting to “none” after saving
- Fixed the Kafka Connect UI becoming inaccessible when any connector returned a null version in its status response
- Fixed the
list_interceptorsModel Context Protocol (MCP) tool failing when called using a personal access token - Fixed the Resource Access tab showing a blank page for teams with KsqlDB or Connector permissions referencing a cluster that no longer exists
- Fixed topic action menus showing destructive options to users with read-only permissions
- Improved performance of
conduktor applywhen applying anApplicationInstancecontaining many resources
Security advisories
CVE-2026-22016 — Java API for XML Processing (JAXP) component
The Eclipse Temurin JDK 21 base image contains CVE-2026-22016, a vulnerability in the Java API for XML Processing (JAXP) component of Oracle Java SE. Exploitation requires the application to use JAXP APIs to process untrusted XML data. Conduktor products do not process XML through JAXP, so the vulnerability is not exploitable in our deployments.CVE-2026-34282 — Networking component
The Eclipse Temurin JDK 21 base image contains CVE-2026-34282, a vulnerability in the Networking component of Oracle Java SE, allowing a denial of service attack. We will issue patched versions of our products once a fix is available upstream.- Breaking changes
- New features
- Preview features
- Deprecated features
- Coming in v3.20.0
- Quality of life improvements
- Fixes
- Security advisories
Breaking changes
Removed Interceptors
The following Interceptors were deprecated in v3.16.0 and have been removed in this release:Affected Interceptors:io.conduktor.gateway.interceptor.ProduceJsonataPluginio.conduktor.gateway.interceptor.FetchJsonataPluginio.conduktor.gateway.interceptor.FetchEncryptPluginio.conduktor.gateway.interceptor.FetchEncryptSchemaBasedPlugin
Duplicate TLS domain names in the keystore
If the Gateway keystore had two or more private key entries whose certificates mapped to the same hostname (overlapping Subject Alternative Name (SAN) or Common Name (CN)), earlier versions kept one entry and ignored the other without reporting an error. From this release, Gateway rejects that configuration and fails to load TLS contexts. The error identifies the conflicting domain. Remove the duplicate key entry or give each entry distinct SANs or CNs so each hostname maps to one certificate.Default for GATEWAY_ACL_ENABLED changed when no network configuration is set
Without any networking configuration (see details below), GATEWAY_ACL_ENABLED now defaults to false regardless of the security mode inferred from the backing Kafka.
This change is part of the new multi-listener configuration zero-config mode, which enables a quick way for developers to get started with Gateway without needing to set up a full network configuration.
In this zero-config mode, Gateway assumes that ACLs are not needed and disables them by default for simplicity.Setting any of the following environment variables will keep the previous default behavior of GATEWAY_ACL_ENABLED (true for GATEWAY_MANAGED, false for KAFKA_MANAGED), ensuring no breaking changes for most production deployments:GATEWAY_SECURITY_PROTOCOLGATEWAY_PORT_STARTGATEWAY_PORT_COUNTGATEWAY_BIND_HOSTGATEWAY_ADVERTISED_HOSTGATEWAY_ADVERTISED_SNI_PORTGATEWAY_ROUTING_MECHANISMGATEWAY_ADVERTISED_HOST_PREFIXGATEWAY_SNI_HOST_SEPARATORGATEWAY_TENANT_IN_HOSTNAME
New features
HAProxy Protocol support
Gateway now supports HAProxy Protocol if enabled by settingGATEWAY_FEATURE_FLAGS_HAPROXY_PROTOCOL to true.This allows it to know the original client IP address (that was replaced by the external load balancer’s own IP address) and then use it in audit logs and error logs. Load balancers like HA Proxy or Nginx supports this protocol.See the complete explanation about HAProxy Protocol.Plan feature coverage
From v3.19.0, Gateway enforces that the features used by newly configured Interceptors are included in your license. The Admin API returns403 Forbidden when you create or update an Interceptor requiring a feature your license doesn’t include, and the response identifies the feature.Preview features
Topic views
Topic views provide non-materialized views of physical Kafka topics, similar to database views. They apply transformations to records as they’re consumed, without modifying the underlying data. In this tech preview, topic views support SQL-based filtering and projection on schema-less JSON. Topic views are an iteration on the SQL Topic Plugin, which is now deprecated.SQLWHERE clauses can filter on record keys, headers, partition, offset and timestampSee the complete guide to topic views.Topic ID support
The Gateway now supports topic-ID based Kafka protocol handling.Initial coverage is limited to the Fetch API. Previously, ApiVersions negotiation advertised Fetch up to v12 to force topic-name fetches; with this feature enabled, clients can negotiate Fetch v13 or higher. Additional APIs will land behind the same flag in upcoming releases.Opt in by setting feature flag via environment variable:${GATEWAY_FEATURE_FLAGS_TOPIC_ID_SUPPORT=true}.As this is a preview feature, we recommend enabling it only in non production environments.Multi-listener updates
This release changes the behavior of the multi-listener configuration (preview):GATEWAY_ACL_ENABLEDis now required, alongsideGATEWAY_SECURITY_MODE. Set it totrueorfalse(typicallytrueforGATEWAY_MANAGED,falseforKAFKA_MANAGED).- Per-listener SSL client authentication: each listener can now have its own mTLS client authentication policy, set via
GATEWAY_LISTENER_<NAME>_SSL_CLIENT_AUTH. The globalGATEWAY_SSL_CLIENT_AUTHenvironment variable is ignored in multi-listener configuration.
Deprecated features
Virtual SQL Topic Plugin
Deprecated in:v3.19.0
Planned removal: v3.22.0
Full plugin name: io.conduktor.gateway.interceptor.VirtualSqlTopicPluginTopic views (tech preview) provide an SQL transformation option which will provide all of the functionality of the SQL Topic Plugin.
Coming in v3.20.0
Internal Kafka client upgrade. Gateway v3.20.0 will upgrade the internal Apache Kafka client from version 3.9 to version 4.0 or later. The upgrade drops support for early versions of some Kafka protocol API keys, but does not change the minimum Kafka broker version that Gateway supports. The change is expected to have low impact for most deployments.Quality of life improvements
Faster bulk Interceptor apply
Bulk Interceptor configuration updates throughconduktor apply and the Admin API are up to 10x faster with lower CPU use than on v3.18.x when you apply many Interceptors in sequence. Simplified Docker image build
The Gateway Docker image is now built from a singleDockerfile, replacing the previous three-stage Maven/Jib pipeline. The runtime entrypoint and HEALTHCHECK behavior are unchanged.If you extend the Gateway image in your own Dockerfile (for example, FROM conduktor/conduktor-gateway:3.18), verify your custom build against 3.19.0, as the internal image layer structure differs from previous releases.Fixes
- The
/metricsendpoint no longer issues blockinglistTopicscalls during scrapes, which could stall the HTTP event loop and cause health-check timeouts in constrained environments.
Security advisories
CVE-2026-22016 — Java API for XML Processing (JAXP) component
The Eclipse Temurin JDK 21 base image contains CVE-2026-22016, a vulnerability in the Java API for XML Processing (JAXP) component of Oracle Java SE. Exploitation requires the application to use JAXP APIs to process untrusted XML data. Conduktor products do not process XML through JAXP, so the vulnerability is not exploitable in our deployments.CVE-2026-34282 — Networking component
The Eclipse Temurin JDK 21 base image contains CVE-2026-34282, a vulnerability in the Networking component of Oracle Java SE, allowing a denial of service attack. We will issue patched versions of our products once a fix is available upstream.Fixes v1.44.1
- Fixed a bug where changing an ApplicationInstance resource’s ownership mode deleted ACLs for the ApplicationInstance’s service account. All customers using Self-service with limited ownership mode should upgrade to this patch release immediately.
- Fixed an authentication issue that caused auto-restart jobs to fail for Connectors created using specific authentication mechanisms.
Breaking changes v1.44.0
Minimum Gateway version v1.44.0
Console 1.44.0 has migrated from Gateway v1 APIs to v2 APIs. This requires Gateway 3.12.0 or later.You’re impacted if
You are running a Gateway version older than 3.12.0 alongside Console.Do you have to do anything?
Upgrade Gateway to 3.12.0 or later before upgrading to Console 1.44.0.Gateway v1 API support will be removed in an upcoming Gateway release. Console versions prior to 1.44.0 will not be compatible with that Gateway release - upgrade Console first.New and updated features v1.44.0
Self-service v1.44.0
Topic prefix support
Self-service now supports requesting and granting access to topic prefixes through the Console UI. This feature enables teams to manage permissions for multiple topics that share a common prefix, streamlining access management for applications that work with groups of related topics.To use this feature, navigate to Application Catalog > Application > select the Application Instance you want to request access from > Ownership section of the Application Instance. From there, you can request access to topic prefixes in addition to individual topics.Transactional ID resources
Self-service now supports TRANSACTIONAL_ID resources for ApplicationInstances and application-managed service accounts, enabling teams to manage transactional IDs as part of their application resources.TRANSACTIONAL_ID resources support the standard ACL operations (Write and Describe). For Confluent Cloud clusters with role bindings enabled, DeveloperRead and DeveloperWrite role bindings are automatically created.This enhancement allows applications using transactional Kafka producers to provision and manage their transactional IDs through Self-service. See the Self-service reference documentation for configuration examples.Insights v1.44.0
RBAC Aware
Insights are now available for all teams using Console. Access is based on the RBAC setup, a user can see insights for the topics where they have permission to view or edit the topic configuration.Focus and Filtering
To provide a more focussed experience when viewing Insights the views have been expanded out into dedicated pages for risks, costs and VIP topics. Across all of these areas the ability to filter the information shown has also been extended, with each view now being filterable by topic name patterns and by the Self-service application owning the resources.These changes allow specific areas of interest of ownership to be analysed, while still providing a high level overview of system health.Quality of life improvements v1.44.0
- Support for Confluent Platform proprietary topic configuration keys when creating topics through the UI and CLI for clusters configured with Confluent Platform as the provider.
- Optimized subject search to be more efficient.
- Added a Bytes as text toggle in topic message details to decode base64-encoded bytes fields as readable UTF-8 text.
- Platform teams can now configure a default number of partitions for topic creation, and custom URLs for the Support and Feedback links in Console. See UI settings properties for details.
Fixes v1.44.0
- Producing Protobuf messages no longer fails when schema references have path-like subject names (e.g.,
org/conduktor/test/schema.proto). - CSV import now detects the topic’s schema format (Avro, JSON Schema, Protobuf) and pre-selects the matching serializer, instead of defaulting to String/JSON.
- Fixed consumer group lag being incorrectly reported as a negative value.
- Fixed consumer group indexing timeout on large clusters when multiple groups share the same topic-partition.
- Fixed an out-of-memory error when indexing clusters with 100K+ consumer group assignments while handling concurrent API requests.
- Fixed message reprocess issue when the payload is large.
- Fixed message reprocess issue when the payload contains NaN value.
- Fixed an issue with schema actions menu being hidden when the schema is in indexing state.
- Fixed scroll bar overlap in the Produce Message panel when all sections are expanded.
- Fixed LDAP authentication failing when group mappings are configured (regression in 1.43.0).
- Fixed Confluent Cloud metrics indexing failing when the telemetry API is accessed through an outbound proxy.
- Fixed Kafka Connect returning 400 errors when accessed through AWS load balancers due to HTTP/2 upgrade headers.
- Fixed message reprocessing failing for Avro messages with timestamp logical types.
Breaking changes v3.18.0
License key required to start Gateway
From v3.18.0, Gateway will only start if a valid license is provided. If you’re already using a license, no changes are required.If you’d like to trial Gateway, contact us.Once you’ve migrated to Gateway v3.18.0, you can remove the license topic_conduktor_gateway_license or _conduktor_${GATEWAY_CLUSTER_ID}_license from your Kafka cluster.Removed external storage option from encryption interceptor
The deprecatedexternalStorage configuration parameter has been removed from encryption Interceptors (EncryptPlugin, FetchEncryptPlugin, EncryptSchemaBasedPlugin, FetchEncryptSchemaBasedPlugin).Impact:- Interceptor configurations containing
externalStorage: truewill fail to load - Messages encrypted with external storage mode cannot be decrypted after upgrading
- The
GATEWAY_ENCRYPTION_CONFIGS_TOPICenvironment variable is no longer used - The
_conduktor_gateway_encryption_configsKafka topic is no longer managed by Gateway
externalStorage: true.If you haven’t migrated yet
Messages encrypted with external storage mode can’t be decrypted after upgrading to v3.18.0.You should:- either downgrade to a version before 3.18.0, decrypt affected data and then re-encrypt using the default header-based storage before upgrading;
- or accept that previously encrypted data using the external storage will no longer be decryptable.
- Remove the
externalStoragefield from your Interceptor configurations. - Optionally delete the orphaned
_conduktor_gateway_encryption_configstopic. Find out more about encryption configuration.
New features v3.18.0
Multiple listeners (preview)
Gateway now supports multiple listeners, allowing you to expose different network endpoints with independent security protocols, routing strategies and network bindings. This is a preview feature and is subject to change.Configure listeners using the newGATEWAY_LISTENER_<NAME>_* environment variables:Message integrity Interceptor
The message integrity Interceptor lets you sign Kafka records on produce and verify them on fetch so consumers can detect if a record was modified after it was produced. Two plugins work together: ProduceIntegrityPolicyPlugin (signs with HMAC-SHA256 via Tink) and FetchIntegrityPolicyPlugin (verifies and drops or allows records by policy). Signing keys are stored in HashiCorp Vault KV v2 and cached locally; credentials are taken from the Interceptor config (including${VAR} placeholders).See Data security for configuration, Vault auth types, and key setup.Deprecated features v3.18.0
Gateway metrics deprecated in v3.18.0
The following three metrics are being deprecated in v3.18.0 and we plan to remove them completely in v3.21.0:gateway_upstream_connections_downstream
Does this affect me?
Yes, if you’re using this metric. Check your Grafana dashboards and alerting rules for references to it.If you have any:- remove all references to the metric.
- replace them with
gateway_active_connections_vclusterto monitor active connections per Virtual Cluster.
Large batch handling plugin
Deprecated in:v3.18.0
Planned removal: v3.21.0
Affected Interceptors:io.conduktor.gateway.interceptor.LargeBatchHandlingPlugin
Fixes v3.18.0
- Improved the masking of secrets across the codebase in case they are ever serialized in logs in the future.
- Fixed the OpenAPI specification, so
UpsertResultenum values are correctly defined as strings, not empty object types. - Added a timeout to
await()operations during shutdown to prevent the process from hanging indefinitely. - Changed the readiness probe to fail during shutdown to prevent the pod from receiving traffic.
- Fixed an issue where TLS connections mid-handshake were not closed properly during shutdown.
- Fixed an issue where the Vault connection intermittently reported an
invalid tokenerror. - Large message Interceptor: added disableChecksums option in S3 config for S3-compatible storage (MinIO, NetApp ONTAP). When set to true, the SDK uses a checksum format that these backends accept. Otherwise, the uploads can fail because the default checksum is not accepted. Find out more about configuring S3.
- Fixed a bug in the ReadOnlyTopic safeguard policy THROTTLE action.
- Improved performance of Gateway when field-level encryption is configured by doing encryption work on separate thread pool.
- Improved performance of field-level encryption by processing partitions in parallel.
- Fixed default Docker healthcheck (e.g. Docker Compose environments).
- Optimized the keep alive re-auth of Fortanix KMS connections with a dynamic refresh mechanism and use of the
refresh()API call. - Gateway’s Vert.x-based admin API server now explicitly disables HTTP/2 cleartext upgrades on the admin API listener and responds over HTTP/1.1
Fixes v1.43.3
- Fixed an issue where navigation failed when Console was configured with a custom base path.
- Fixed an issue where logging output was too verbose.
- Updated the base image to include upstream patches for CVE-2026-24308 and CVE-2026-29062.
Fixes v1.43.2
- Reduced memory usage and improved performance of the Consumer Group Indexer task.
- Fixed an issue where the “Create Connector” button was not displayed for users with permission to create connectors.
Fixes v3.17.2
- Disabled topic ID support to resolve a known issue. This will be re-enabled in a future release once the issue is resolved.
Fixes v1.43.1
- Reduced the risk of sensitive information appearing in logs when Console is configured to log at DEBUG level.
- Fixed an issue where some identity pools in the service account UI failed to retrieve identity pool information correctly.
- Conduktor Scale:
- Quality of life improvements
- Fixes
- Upcoming changes: deprecation notice for Self-service topic policies
Conduktor Scale
Community Edition
We’ve overhauled our free license. If you’re currently using it, the changes will only be applied when you upgrade to Console v1.43.0.Find out more about the Community Edition.Quality of life improvements v1.43.0
- Added support for Boolean, Short, Int and UUID format types when producing and consuming topic messages.
- Kafka Connect UI now enforces RBAC permissions and hides actions the user is not permitted to perform.
- Moved the MCP navigation link to the Settings page to reduce the number of items in the main menu.
- Added support for managing Kafka Connect connector resource policies in the UI.
- Improved the Topic consume page to return more explicit errors and to include a retry option.
- Added a new
Kafka.ConsumerGroup.Createevent type that tracks consumer group creation events in the audit log. - Added a public API endpoint to manage Kafka Connect connectors’ auto-restart.
Fixes v1.43.0
- The Request access button in the Topic Catalog is now disabled when the user doesn’t own any applications.
- After deleting a cluster, the deletion dialog now closes and cluster list is refreshed.
- Alert history now shows correct time ranges for 1D/7D/30D views and accurate tooltip dates spanning midnight.
- The Reset Offset and Add Partitions drawers now stay open as expected on Firefox ESR.
- The
CDK_DATAPOLICY_DISABLEKEYMASKINGsetting now correctly disables key masking in data policies. - Exporting large topic messages (over 100 KB) now includes the full message content instead of empty values.
- Connector auto-restart settings are no longer unexpectedly disabled when connectors are temporarily unavailable.
Upcoming deprecation notice v1.43.0
Self-service topic policies will be deprecated in Console v1.46.0. We recommend that you convert all your existing topic policies to resource policies as soon as possible. The resource policies have feature parity with the legacy topic policies.Use the Console UI to do this easily: go to Settings > Policies migration.Fixes v3.17.1
- Fixed a bug where consumer group names and transaction IDs containing colons caused an error in the Virtual Cluster passthrough mode.
- Fixed
DescribeGroupsreturning incorrect groupInstanceId in the multi-tenant mode.
- Conduktor Scale:
- Quality of life improvements
- Fixes
Conduktor Scale
Chargeback without Gateway
This Console version introduces new Chargeback capabilities that do not require Gateway. Metrics and costs can be viewed by application, application instance and topic.Find out more about Chargeback without Gateway.Insights filtering and sorting
The Insights dashboard now offers enhanced filtering, sorting and search capabilities:- Global filtering - filter all Insights data by label or topic type (internal, streams, user). Click any label in a table to apply it as a filter.
- Sorting and searching - tables in risk analysis, VIP topics and governance sections now support column sorting and search.
- Topic classification - topic type labels are now shown alongside custom labels for easier identification.
- Filtered exports - when filters are applied, exported CSV files include a -filtered suffix and contain only the filtered data.
Cluster wide resource policies
Platform teams can now enforce resource policies at the cluster level, ensuring that all your Kafka resources follow the best practices across the entire platform.With cluster-wide policies, you can set standards across all the resources for replication factor, minimum in-sync replicas, schema restrictions and much more, without having to specify them individually for each application.New resource policies page
The new Resource policies page replaces the Topic Policies page and provides a centralized view of all the policies with enhanced filtering and navigation.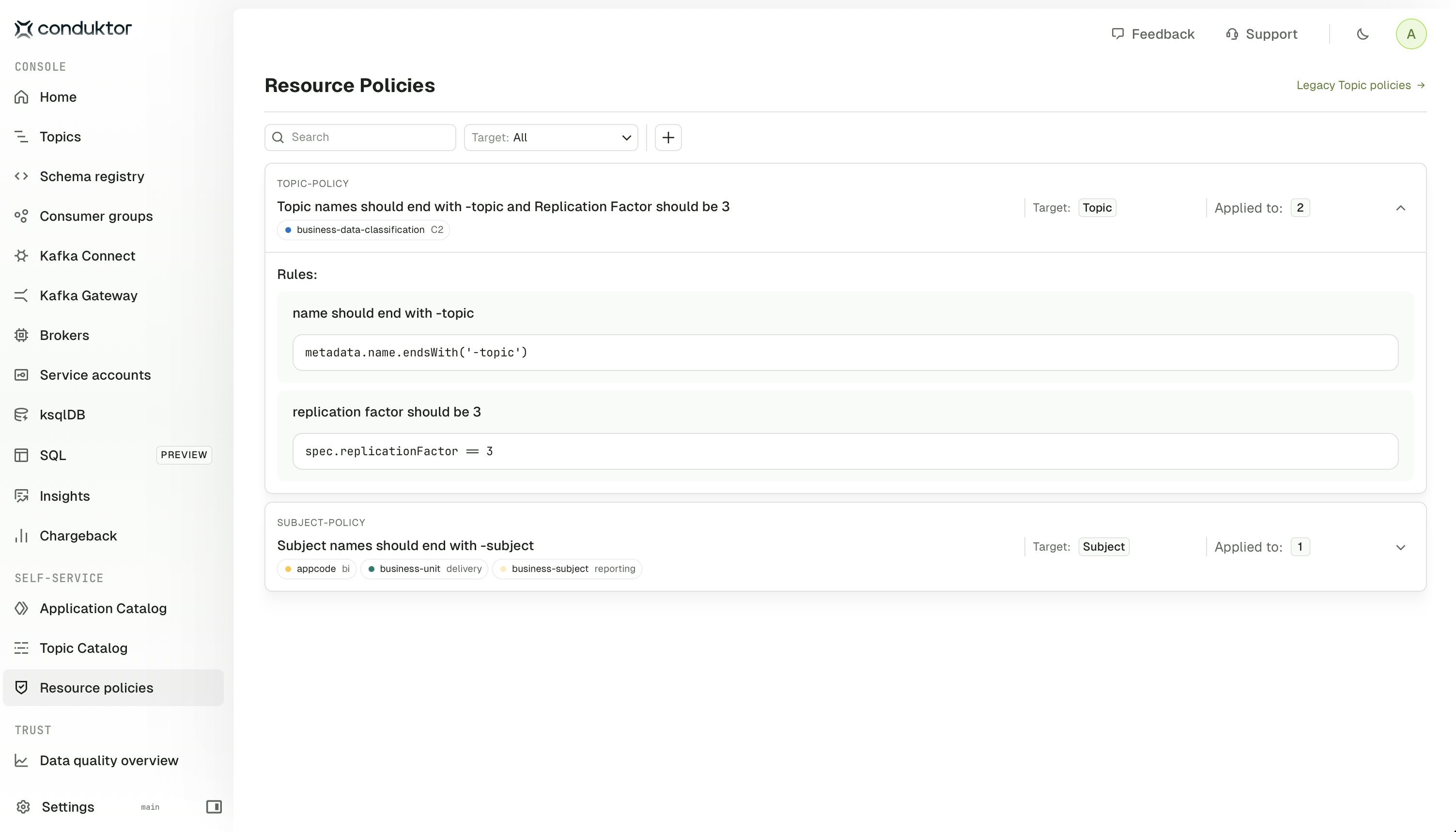
Quality of life improvements v1.42.0
- Added support for optional basic auth for the metric scraping endpoints (
/api/monitoring/metricsand/monitoring/metrics/). To configure, useCDK_MONITORING_BASICAUTH_EMAILandCDK_MONITORING_BASICAUTH_PASSWORD. Find out more. - Sensitive information such as passwords, tokens, keys and secrets are now redacted in audit logs.
- Made a number of visual improvements to the topic consume message drawer
- Added support for environment variables in webhook alert configurations, allowing secrets to be injected securely using
{{env.*}}syntax (for environment variables prefixed withCDK_WEBHOOK_, with the prefix stripped). - Added basic authentication support for outbound Prometheus/Cortex/Mimir queries via the
monitoring.prometheus-authconfiguration. - Added a new consumer value format
SchemaRegistryto prevent a poison pill when the first record(s) are not in the expected format. - Refactored topic indexing to reduce memory consumption and remove hard-coded timeout for retrieving offsets.
- Refactored consumer group indexing to reduce the number of queries to the database.
- Cluster selection menu moved to the top of the page for better user experience.
Fixes v1.42.0
- Fixed Reset Topics functionality for some Kafka Connect servers where topics weren’t being correctly refreshed.
- Fixed a bug where identity providers for Confluent Cloud weren’t displaying all known identity providers in the Service Accounts UI.
- Fixed override of
CDK_GLOBAL_JAVA_OPTSenvironment variable that was not working as expected. - Fixed an error that occurred when Confluent CLI applied new subject with
--dry-run. - Fixed the group v2 API to include ksqlDB permissions in the response.
- Fixed performance regression on the group v2 API
- Exporting large topic messages no longer results in empty values for truncated data.
- Improved login performance for LDAP users with many groups.
- Changed the topic list implementation to query the database instead of kafka, allowing a much faster response.
- The logical connector ID is now displayed for Confluent Cloud managed connectors.
- Fixed ksqlDB custom headers not being applied, which prevented combining mTLS authentication with Basic Auth headers.
- Fixed AWS Glue schema ID display in consumed messages - UUID-based schema IDs are now handled correctly without causing errors.
- Added configuration of PKCE method for better support of OIDC providers.
- New features
- Deprecated features:
- Fixes
- Quality of life improvements
New features
Support for Vault Transform Secrets Engine
Gateway’s encryption/decryption Interceptors now support the Vault Transform Secrets Engine in addition to the default Transit Secrets Engine.This means that Gateway now provides an alternative method for protecting sensitive data in Kafka messages: tokenization and format-preserving encryption:- tokenization: sensitive data is replaced with tokens that are deterministically generated when the same key is used, while also storing the original values securely in HashiCorp Vault’s transform secrets engine.
- format-preserving encryption: data is still encrypted but the format and length of the original field data is preserved.
EncryptPlugin, DecryptPlugin, etc.).Simply specify a vault-transform:// prefix in your keySecretId (e.g. vault-transform://my-role).Find out more about Vault KMS configuration.Low level network configuration
Added the ability to customize some of the low level network configuration.Deprecated features v3.17.0
Filtering topics with CEL
Deprecated in:v3.17.0
Planned removal: v3.20.0
Full plugin name: - io.conduktor.gateway.interceptor.CelTopicPluginTopic views (tech preview) provide an will provide a CEL transformation option in a future release which will provide all of the functionality of the CEL Topic Plugin.
Fixes v3.17.0
- If Confluent Cloud Principal Resolver is configured, the Confluent Cloud API Secret is now masked.
- Fixed a bug causing duplicate broker connections and incorrect client disconnections.
- Fixed FindCoordinator to preserve all Kafka error codes instead of incorrectly converting them to
COORDINATOR_NOT_AVAILABLE, ensuring clients receive accurate error information from Kafka. - Fixed Fetch v16 response handling to prevent invalid MessageSetSize errors
Quality of life improvements v3.17.0
- General improvements to log messages for better readability and clarity.
- Adjusted log level for better operational visibility.
- Breaking changes
- Conduktor Scale:
- Conduktor Shield
- Conduktor Trust
- Quality of life improvements
- Fixes
Breaking changes v1.41.0
If you currently use Chargeback, please note that we have folded this into a broader Chargeback feature, including costs based on topic storage and partitions. To continue to use the existing feature you will need to set an environment variable, documented here.This will also enable the new Chargeback functionality that does not depend upon Gateway.Conduktor Scale
MCP server
Preview functionality: This is currently a preview feature and is subject to change as we continue working on it.
Chargeback without Gateway
This Console version introduces Chargeback for storage and partitions which allows tracking of byte and partition usage across clusters.It works directly with Console’s metadata indexer - there’s no need to set up or maintain Gateway.You can:- track costs based on storage consumption (byte-hours) and partition counts (partition-hours) per topic,
- view costs aggregated by day or month, with percentage attribution showing each cluster’s contribution to total spend,
- set cost rates per cluster for both storage and partitions,
- see overall costs, storage-only costs, or partition-only costs.
Configurable context path
Console now supports context path configuration for deployments such ashttps://company.com/conduktor. This is especially useful for restricted Kubernetes environments with ingress controllers. Find out how to deploy with a context path.Key masking in data policies can be disabled
Data masking policies for keys that are not JSON or schema-based can be disabled.Find out about data policy properties.Conduktor Trust
Added onboarding banners to the Rules and Policies pages to help users get started with data quality.The banners will disappear as soon as you create your first Rule or Policy.Find out about data quality.Quality of life improvements v1.41.0
- Refactored topic and consumer group indexing tasks to reduce load on Kafka clusters and improve CPU and memory usage. Timeouts may need to be adjusted to align with the updated duration of these indexing tasks.
- Added usage data to help admins track Console usage and monitor license utilization. Admins can view active users, see Self-service applications and instances, access requests, view total Partner Zones and shared topics across three time periods: last 30 days, current month and the last 12 months. This feature includes a monthly trends graph and CSV export for offline analysis. Historical data builds up over time as Console collects usage metrics. Find out more about usage data.
- The consumer group offset lag graph previously displayed the max offset lag value, but has been adjusted to display the sum value to correspond with its alerting behaviour.
Fixes v1.41.0
- Resolved IO exceptions that were happening for customers with long-running queries.
- Improved performance of Insights data collection by 2-3x through various optimizations, reducing resource usage and speeding up metrics gathering.
- Adjusted default Insights refresh frequency from 5 minutes to 15 minutes, freeing up system resources.
- ksqlDB server configuration now accepts the authorization HTTP header, allowing you to use both SSL and basic authentication.
- Added configuration option to disable data masking on record keys, allowing you to see and filter by keys that are not structured data.
- Self-service RBAC operations now happen in a single transaction, preventing incomplete object creation when deploying via CI/CD.
- Conduktor CLI dry-run mode now correctly reports
NotChangedwhen there are no actual changes to Self-service application resources.
- Breaking changes:
- New features:
- Deprecated features:
- Fixes
Breaking changes
The metric gateway_license_remaining_days is now a positive number
If you have set up any alerts on the metric gateway_license_remaining_days in your own monitoring stack, please check them prior to this release.
The metric was incorrectly reporting a negative number when time remained on the license, and this has now been corrected.New features
New v2 APIs for clusters
The v2 API now supports cluster switching operations and retrieving physical cluster connection configurations.A new endpointv2/cluster-switching/check is available to check which physical cluster is currently active (main or failover).Check out the Gateway v2 API reference for more details.Support for Fortanix KMS
Gateway now supports field-level and full payload encryption/decryption using Fortanix Data Security Manager (DSM) as the Key Management Service (KMS). This integration enables secure encryption of Kafka messages with keys managed by Fortanix. Find out how to configure Fortanix KMS.Deprecated features v3.16.0
Fetch encryption Interceptors
Deprecated in:v3.16.0
Planned removal: v3.19.0
Affected Interceptors:io.conduktor.gateway.interceptor.FetchEncryptPluginio.conduktor.gateway.interceptor.FetchEncryptSchemaBasedPlugin
JSONata transformer Interceptors
Deprecated in:v3.16.0
Planned removal: v3.19.0
Affected Interceptors:io.conduktor.gateway.interceptor.FetchJsonataPluginio.conduktor.gateway.interceptor.ProduceJsonataPlugin
The GATEWAY_INTERCEPTOR_CONFIG_LOCATION environment variable
Deprecated in:v3.16.0
Planned removal: v3.19.0This variable allowed users to configure global Interceptors by pointing to a configuration file location.We recommend using Gitops tooling instead.Delegated security modes
Deprecated in:v3.10.0
Planned removal: v3.19.0We’ll remove support for delegated security modes in v3.19.0. Currently, we support backwards compatibility for configurations using DELEGATED_XXX environment variables.If you’re still using these, you should migrate to the GATEWAY_SECURITY_MODE. Check out the migration guide.Fixes v3.16.0
- The metric
gateway_license_remaining_daysis now a positive number when there is time remaining on the license, instead of negative. - Gateway now preserves upstream Kafka errors in metadata responses instead of unconditionally overwriting them with unknown topic errors, allowing clients to see the actual error from Kafka.
- Data masking now gracefully skips records with full payload encryption headers, preventing errors when both Interceptors are applied to the same topic. This applies when using header-based encryption storage (
externalStorage: falsewhich is the default).
- Conduktor Exchange:
- Conduktor Scale:
- Quality of life improvements
- Fixes
Breaking changes - Partner Zone PENDING status
ThePENDING status has been replaced with:PENDING_CREATEon initial creationPENDING_UPDATEon subsequent updates
PENDING_UPDATE.The Partner Zone status appears only in the API responses and will not have impact on usage of the CLI.Conduktor Scale
SSO login
Console now supports browser-based Single Sign-On (SSO) with external JWT tokens. Once users are authenticated to their organization’s Identity Provider, they are also automatically logged in to Console.This feature supports organizations that require centralized authentication management and provides a seamless single sign-on experience across applications.Find out more about configuring browser-based SSO with external JWT tokens.Enhanced login and onboarding experience
The login and onboarding experience has been redesigned with a modern, streamlined interface. The updated design improves visual consistency, enhances usability, and provides a more intuitive user experience for both new and returning users.Topic size information for Confluent Cloud topics
We now support showing Confluent Cloud topic sizes (storage in bytes) throughout the product.To enable visibility of topic storage information for Confluent Cloud clusters, you have to configure the Confluent Cloud provider and add a Confluent Cloud API key with the MetricsViewer role.Quality of life improvements v1.40.0
- Improved Insights dashboard user experience with enhanced usability and navigation.
- CSV export of Insights data now supports zip compression for easier file management.
- Labels filter dropdown now supports search functionality for easier label selection.
- Improved navigation in Topic Catalog with clickable links to the application, instance, and owner group.
- Added
database.optionsandkafka_sql.database.optionsconfiguration to pass any valid JDBC or Hikari options, as an alternative todatabase.urlandkafka_sql.database.url, respectively. Find out more about Console database properties. - We have added the new metric
console_license_remaining_dayswhich can be used to monitor the remaining days on your console license.
Fixes v1.40.0
- The connector form didn’t update when switching connector type during creation. This has now been resolved.
- Duplicate operationId values in the OpenAPI specification prevented code generation with openapi-generator-cli. The specification has been corrected.
- The Group API returned an error when KsqlDB permission was added. This error has been resolved.
- After upgrading to 1.38, users with permissions on all clusters lost menu visibility of brokers and service accounts entries. This visibility issue has been resolved.
- Creating topics sometimes showed misleading error messages when redirecting before indexing completed. These messages are now accurate.
- Metrics didn’t display in large clusters due to timeout errors when fetching topic offsets. This timeout issue has been resolved.
- Database indexing failed after PostgreSQL restarts. Connection resilience has been improved with the new
database.optionsconfiguration. - Resolved migration issue that could affect customers using more than one subject naming strategy when upgrading from 1.38 to 1.39
Breaking changes v3.15.0
Block admin operation APIs
This release blocks 15 low-level admin operation APIs that should be executed directly on the underlying Kafka cluster rather than through Gateway. These APIs have been reclassified from passthrough-supported to stability-blocked.Why this change? The low-level admin operations do not align with Gateway’s security controls and must be performed through direct cluster access.How to know if you’re impacted:- Before upgrading, review your applications and scripts to identify any code using these APIs through Gateway.
- After upgrading:
- Monitor your logs for errors related to:
ALTER_REPLICA_LOG_DIRS,ELECT_LEADERS,ALTER_PARTITION_REASSIGNMENTS,LIST_PARTITION_REASSIGNMENTS,ALTER_PARTITION,ALLOCATE_PRODUCER_IDS,CREATE_DELEGATION_TOKEN,RENEW_DELEGATION_TOKEN,EXPIRE_DELEGATION_TOKEN,DESCRIBE_DELEGATION_TOKEN,DESCRIBE_USER_SCRAM_CREDENTIALS,ALTER_USER_SCRAM_CREDENTIALS,DESCRIBE_CLIENT_QUOTAS,ALTER_CLIENT_QUOTAS,UPDATE_FEATURES - Check Gateway error responses indicating blocked API calls
- Monitor your logs for errors related to:
- Update your applications and workflows to perform admin operations with direct cluster access instead of through Gateway
Deprecating v1 APIs
v1 APIs are now deprecated in favor of the v2 APIs introduced in Gateway 3.3.0 in September 2024.If you’re using the Conduktor CLI to operate Gateway, you are not impacted.Check out the Gateway API reference to see which APIs are affected.All the v1 APIs will be no longer available from Gateway v3.18.0.If you’re using the v1 APIs, please migrate to the v2 APIs as soon as possible. Get in touch if you need support with this migration.The externalStorage option in encryption interceptors is deprecated
TheexternalStorage configuration parameter in encryption Interceptors (EncryptPlugin, FetchEncryptPlugin, EncryptSchemaBasedPlugin, FetchEncryptSchemaBasedPlugin) is now deprecated and will be removed in Gateway 3.18.0.This parameter controls whether encryption settings are stored in message headers (false, default) or in a separate topic (true).Action required: If you’re currently using externalStorage: true, you should plan to migrate to the default behavior (storing encryption settings in message headers) before upgrading to Gateway 3.18.0. Find out more about encryption configuration.Fixes v3.15.0
- Fixed issue where multiple encryption interceptors could not be applied to the same topic, now allowing priority-based selection.
- Fixed NullPointerException during Gateway startup when interceptor version constraints specify only min or max values.
- Updated
TopicRequiredSchemaIdPolicyPluginto allow tombstone records (NULL values) in compacted topics, while still requiring schema IDs for non-null records.
Quality of life improvements v3.15.0
- When ACL is enabled in
GATEWAY_MANAGEDsecurity mode, authorization failure will contain additional information in the message like these:
- Conduktor Scale:
- Conduktor Exchange:
- Conduktor Trust:
- Fixes
- Known issues v1.39.0
Conduktor Scale
Insights
The brand new Insights dashboard in Console provides a comprehensive analysis of your Kafka infrastructure, helping platform teams to:- proactively identify configuration issues,
- optimize storage costs,
- track governance metrics,
- monitor business-critical topics and more.
Collection of product metrics
The global property,enable_product_metrics, with the corresponding environment variable CDK_ENABLE_PRODUCT_METRICS has been updated so that it is only configurable with an enterprise license. Without an enterprise license this property will always
default to true meaning product metrics will always be collected by Conduktor.Data quality observability
Data quality observability enables teams to understand data quality patterns across their entire Kafka environment before making decisions.Data quality Policies can now be configured for non-Gateway topics using the observe action to gather metrics on messages that fail data quality Rules.Find out more about data quality observability with Conduktor.Conduktor Exchange
Partner Zone traffic analytics tab
You can now show traffic analytics for a Partner Zone using the new Traffic tab on the Partner Zone list page. The analytics will only be displayed for Gateway clusters that have the observability Interceptor enabled.The new tab includes a chart and a table for each Partner Zone for data egress, ingress and all traffic with the option to export this data as a CSV file.To enable Partner Zone analytics, existing observability Interceptors with a non-global scope (where the vcluster scope is set topassthrough) will have to be deleted and re-created with a global scope.Find out about how to configure Partner Zone traffic analytics in Console.Fixes v1.39.0
- Added support for SSL connections without authentication when configuring Kafka clusters
- Fixed http 500 error when forcing a consumer group rebalance
- Fixed an issue where application instance permissions were being created despite API request validation failures
- Fixed duplicate operation IDs in OpenAPI specification which caused errors when using OpenAPI code generation tooling
- Fixed error preventing the user from changing schema compatibility or deleting schemas with forward slashes in their names
Known issue v1.39.0
If you’re using more than one subject naming strategy, migrating to v1.39.0 might fail.If you see an error message similar toMigration of schema "cdk_admin" to version "184 - add unique index to topic analytics" failed!, skip this release and upgrade directly to 1.40 or later.New feature v3.14.0
Added SSL configuration for Vault KMS with support for trust store (TLS) and key store (mTLS). Find out more about Vault KMS.Fix v3.14.0
Added configuration options for TLS cipher suites and protocols to allow customization of SSL/TLS security settings.New feature
Support restriction of TLS protocols and cipher suites
Introduced optional environment variables to allow for restriction of which TLS protocols and cipher suites the Gateway server offers during the TLS handshake. Find out more.- Conduktor Scale:
- Conduktor Exchange:
- Conduktor Trust:
- Quality of life improvements
- Fixes
Conduktor Scale
Application instance access
The new Access tab provides a detailed view of:- All topics this application instance has access to, with the ability to remove this access if you are a member of the owner group for the application.
- All topics this application instance has granted access to, with the ability to revoke this access if you are a member of the owner group for the application.
The GitOps approved icon will not appear for CLI-created application instance permissions in the Outgoing access section.
Topic catalog access
Displays all applications and application instances with access to this topic:- You can remove access for your own applications.
- If you’re a member of the application owner group of this topic, you can revoke access for other applications.
Grant access to a topic
Access to a topic can now be granted from the topic details page.Remove or revoke access request
The access request modal now supports removing or revoking access for approved requests based on user role:- Application owners: can revoke access using Revoke access in the request details drawer
- Access requesters: can remove their own access with Remove access in the request details drawer
Confluent Cloud role binding support for Self-service
You can now manage service accounts through Confluent Cloud RBAC role-bindings. This provides the added benefit of provisioning permissions for the subject resources via schema registry RBAC role bindings.For example, a topic request that seekswrite access to another ApplicationInstance’s topic will result in the associated application instance’s service account receiving a DeveloperWrite and DeveloperRead role binding.Find out how to migrate RBAC role bindings to Confluent Cloud.Migrate topic policies
Topic policies will be deprecated in an upcoming release. Please use resource policies with atargetKind of Topic instead.You can migrate the existing topic policies using the Console UI. Go to Settings > Policies migration and click Migrate Policies to migrate the topic policies to resource policies.
- If a topic policy is migrated and the new resource policy is then deleted, the topic policy can’t be migrated a second time.
- If a topic policy is migrated and then deleted, then a new topic policy is created with same name as the old one, but the ‘new’ policy can’t be migrated.
- If a topic policy is migrated and then updated, it can’t be migrated again.
- When you migrate topic policies, all the application instances referring to those policies will have both the newly migrated resource and the old topic policies. The topic policies will be removed automatically when this feature is deprecated in a future release.
Support for external monitoring solutions
Console now supports the configuration of external monitoring solutions, including Cortex, Mimir and Prometheus.These can be used instead of the defaultconduktor-console-cortex image.Multi-tenancy is also supported.Conduktor Exchange
Partner Zone enhancements
- Partner Zones now support specifying a custom Virtual Cluster name with
vclusterNamewhen using the API or CLI. This provides better control over naming conventions and simplifies migration from existing Virtual Clusters. - You can now download CA certificates associated with a Partner Zone from the Console UI. This makes sharing certificates with your partners much easier. Find out how to download certificates.
Conduktor Trust
Validate your Rule against sample messages
Added the ability to test data quality Rules with sample data before creation. Find out more about testing Rules before creation.Custom data quality Rule violation messages
You can now define a custom message that replaces the default[RULE_NAME] did not pass when a Rule is violated. Find out how to set the custom message during Rule creation.Edit attached Rules from the Policy details page
Added the ability to modify which Rules are attached to a Policy directly from the Policy details page. Find out more about editing attached Rules.Quality of life improvements v1.38.0
We’ve completely redesigned the main cluster selector, introducing a number of usability improvements:- Added an option to pin clusters - your frequently used ones can now be pinned to the top of the list
- Improved keyboard navigation for faster cluster switching and enhanced accessibility
- For admins, added the ability to easily jump to the configuration page for any cluster
Fixes v1.38.0
- Fixed an issue where closing the templates drawer in the topic consume view would prevent the user from interacting with the rest of the page.
- Fixed searching within groups to allow filtering on “contains” instead of “starts with” for improved search experience.
- Fixed SSO configuration to support configurable email claims for special identity types.
- Fixed connector creation modal to show validation warnings instead of blocking creation, allowing you to proceed with caution (matching CLI behavior).
- Fixed access control vulnerabilities preventing low-privileged users from accessing and modifying data masking policies.
- Fixed ‘Last active’ sorting in group members list to properly handle users who have never been active.
- Fixed SQL indexed topics page to stay on the correct tab when refreshing instead of redirecting to a different URL.
- Fixed duplicate topic subscription requests for already approved subscriptions in the Self-service catalog.
- Fixed record view to show header keys in their original casing instead of uppercase.
- Fixed topic template duplication functionality that was failing silently.
- Fixed cluster creation validation to prevent duplicate technical IDs with better user experience.
- Fixed data policies display layout to properly wrap field badges and prevent overlap.
- Fixed CEL expression evaluation in resource policies to handle missing spec.configs correctly.
New features v3.13.0
Enhanced audit logging for authorization failures
- An audit log event is now generated for authorization failures (when ACL permissions deny an operation on a resource). Find out more about the authorization failure events.
- Improved error message verbosity with
enableDetailedErrorLoggingproperty in GCP KMS exception handling. Find out more about the GCP KMS configuration.
Block unsupported APIs with Gateway
This release introduces theGATEWAY_FEATURE_FLAGS_BLOCK_UNSUPPORTED_APIS environment variable which gives you control over how Gateway handles Kafka APIs that aren’t explicitly supported.See the full configuration details and usage modes.New encryption error policy
AddederrorPolicy configuration to encryption Interceptors that allows skipping already encrypted messages.The default behavior maintains current functionality (an exception is thrown). To allow skipping, add this new option to your configuration.See configuration details in the Interceptor Reference.Quality of life improvement v3.13.0
Added blacklist configuration support to the topic policy. Check out more about the CreateTopicPolicyPlugin.Fixes v3.13.0
- Fixed the principal resolver failure to resolve the Confluent Cloud service account from an API Key.
- Added round-robin Gateway endpoint allocation to prevent all traffic from being directed to the same Gateway node. Find out more about Gateway internal load balancing.
- Improved customer experience for Vault KMS configuration by removing a confusing version field. The encryption Interceptor uses Vault Transit engine which only supports version 1 (hardcoded), but the configuration incorrectly exposed it as configurable. This change removes the misleading field from configuration examples while maintaining backward compatibility.
- Fixed the error when connecting with super user and Virtual Cluster(s) is mandatory.
- Fixed Fetch Policy Interceptor isolation level configuration to accept lowercase values, matching Kafka standards.
- Fixed Confluent Cloud principal resolver to handle API keys for both service accounts and user accounts.
- Fixed Azure OAuth authentication method priority to respect explicit configuration over environment variables.
- Relaxed name validation in service-account v2 API to support dots, equals signs, and commas.
Fixes v1.37.1
- Fixed an issue where resource policies were not applied when editing application groups from the UI.
- Fixed an issue where members from external groups were not synchronized if an application group without permissions existed.
- Breaking changes
- Conduktor Scale:
- Conduktor Exchange:
- Conduktor Trust:
- Quality of life improvements
- Fixes
Breaking changes v1.37.0
Gateway 3.12 dependency
Starting from Console 1.37, Conduktor Trust Mark action and Conduktor Exchange Partner Zone functionality will require Gateway 3.12 or later.Email address storage
In this release, we’ve made a change to how we store user email addresses in Console. All emails are now stored in lowercase to ensure consistency and prevent issues with SSO or RBAC.Prometheus configuration overrides
Before Console v1.37.0, Prometheus configuration was overridden using the replace strategy. Since v1.37.0 it’s changed to the patch (YAML merging) strategy.Prometheus configuration can be patched by mounting a YAML file to path/opt/override-configs/prometheus.yaml. To set an alternative path, use the PROMETHEUS_OVERRIDE_CONFIG_FILE environment variable.Conduktor Scale
Application groups management
New application group management in Self-service provides full lifecycle management through improved UI workflows.The Members tab offers an enhanced interface for managing group membership, making it easier for teams to control access and visibility. The Resource access tab enables granular control over topic, consumer group, subject, and connector permissions for precise access management. Application groups can also map to external groups like Console user groups for streamlined access management.Application Instance resources
Application instances now feature comprehensive resource management capabilities. The new Resources tab provides a detailed view of all the resources associated with application instances, giving teams better visibility into their resource usage and dependencies.Subject strategies support
Support for Confluent subject strategies has been added to the produce page for topics. This enhancement gives users more control over how schemas are referenced when producing messages, providing flexibility in schema organization and naming conventions.External group management improvements
The External groups UI has been enhanced for mapping external authentication groups, making it easier for administrators to configure and maintain user access patterns.Both the Console user groups and application groups now support external group regex functionality, enabling dynamic group assignment based on external authentication patterns. This allows organizations to automatically map users from identity providers to appropriate application groups, based on configurable regex patterns.Conduktor Exchange
Partner Zone out of preview
Partner Zones are now generally available and out of preview. This means that all features are fully supported, production-ready, and can be used in production environments.Partner Zone multi-cluster support
Console now supports creating Partner Zones against a multi-clustered Gateway configuration. This allows for a Partner Zone to be created against any of the configured Kafka clusters behind Gateway (previously, a Gateway was required per Kafka cluster for a Partner Zone).Check out the tutorial on creating Partner Zones with multi-cluster Gateway, as well as the Console resources for Partner Zones.Partner Zone breaking changes
With the multi-cluster support in Gateway 3.12, all existing Partner Zones created prior to this version of Console are incompatible and cannot be migrated or updated to support the new capability. Hence, existing Partner Zones will stop functioning after the upgrade if not recreated.Conduktor Trust
Regex library
Added an option to Show regex library when creating a new rule in Console. This provides a list of pre-built regex examples that can be used to speed up rule creation.Mark action
You can now toggle the Mark action on data quality Policies. When enabled, messages that violate the rule(s) are tagged with a special header.Check out the Mark action use case.JSON schema rule type
You can now create JSON schema rules to validate message structure and content.Check out the JSON schema use case.Quality of life improvements v1.37.0
You can now fine-tune Cortex and Prometheus retention with the new environment variables. We’ve also updated the default values to reduce disk usage.You can patch (instead of replacing) the YAML configuration. Find out more about overriding the configuration with YAML.The Self-service experience has been improved with updated terminology for managing access requests.Ambiguous and inconsistent references to various terminology such as ‘subscriptions’, ‘subscribing’, ‘access requests’, ‘sharing’, ‘requests’, have been standardized throughout the application, placing emphasis on a single unified concept of access request.You can now view the Resource Policies in the Application details page, and the Consumer Group ownerships in the Application instance details page.The Trust Rules and Policies pages are now hidden for users without Trust in their license.Fixes v1.37.0
- Fixed production rate metrics getting stuck at high values when producer rates drop instantly to zero, which was causing artificially inflated metrics in systems with bursty production patterns.
- Errors preventing users from logging in are now prominently displayed on the login page.
- To prevent disclosure of password length in configuration forms, password fields are now consistently obfuscated regardless of the length of the actual password.
- Secrets in AWS Glue and other cluster configuration forms are no longer shown in clear text.
- Fixed error logs appearing when SQL features are not enabled, reducing unnecessary log noise.
- Fixed onboarding page checkbox labels not being clickable, improving user experience during account setup.
- Schema registry naming strategies now include namespace in generated subject names.
- Fixed issue where topic navigation tab was missing from main menu for certain user roles despite having proper permissions.
- Self-service configuration now correctly handles multiple Kafka Connect clusters connected to a single application instance.
- Duplicate users can no longer be created using the same email username but in different casing.
- In the metadata of the records, the schema names are no longer truncated.
- Add error messages on Connector failure, helping troubleshooting.
- Fixed topic policies not being visible in application instances after upgrading from version 1.35 to 1.36.
- Fixed a ‘404 group does not exist’ error incorrectly showing up when upgrading from version 1.35 to 1.36.
- Deleting the Kafka Connect cluster now deletes the associated permissions, solving the permission errors on user and group GET operations.
- Improved groups API performance, preventing timeouts for big organizations with thousands of users and groups.
- Improved indexer performance, preventing timeouts for big organizations with thousands of consumer groups.
- JVM metrics renamed in the Console and the Grafana dashboard, based on Prometheus changes.
Breaking changes v3.12.0
New APIs for health and versions
To improve the reliability and monitoring of the Gateway service, we’ve introduced new API endpoints for health checks and version information.These changes align our service with Kubernetes health check standards and will provide a more robust way to monitor Gateway’s status.Find out more from the monitoring reference.Rename of Virtual Cluster Id
When a Kafka client requests the cluster Id of a Virtual Cluster through Gateway, the returned cluster Id will be different - it will be renamed.Previously, the returned cluster Id was the native Kafka cluster Id of the Virtual Cluster’s physical cluster.The new cluster Id that’s returned will be be in the form of:{virtual-cluster-name}@{physical-cluster-id}.New features v3.12.0
New environment variable
This release introduces theGATEWAY_AUDIT_LOG_EVENT_TYPES environment variable which controls the types of events recorded in the audit log.It provides flexibility to enable/disable specific event types, such as CONNECTION.See the full list and explanations of the event types.This change is backwards compatible, as the default value is ALL (which means that all event types are logged by default).Enhanced crypto shredding behavior for decryption
The decryption Interceptor now includes improved error handling behavior specifically for crypto shredding scenarios.A newcrypto_shred_safe_fail_fetch error policy has been introduced. It returns encrypted data when decryption fails due to missing encryption keys, but throws exceptions for other types of decryption failures (e.g., authentication errors). This ensures that crypto-shredded data remains protected while still failing fast for other issues that require attention.Client throttling for encryption and decryption
Gateway now supports client throttling when encryption or decryption operations fail, helping to protect your system from being overwhelmed during error conditions.- New throttleTimeMs configuration: Set
throttleTimeMsto control how long clients will be throttled when encryption/decryption fails (in milliseconds, default: 0) - Automatic system protection: When encryption or decryption fails, Gateway can automatically throttle the problematic client for the specified duration, preventing system overload
- Configurable behavior: You can enable and adjust throttling based on your system’s needs and error tolerance
Fixes v3.12.0
-
KUBERNETESVault authentication now gets the JWT from the default Vault location (/var/run/secrets/kubernetes.io/serviceaccount/token). You can configure this location usingpath(VAULT_KUBERNETES_PATH). Thejwtconfiguration key is no longer needed. See Kubernetes authentication under Vault authentication types. -
Enriched the
REST_APIaudit log events with the request body, which was previously not captured. -
Resolved
GATEWAY_TOPIC_STORE_KCACHE_REPLICATION_FACTORconfiguration to properly default to the Kafka cluster’s default replication factor settings. -
Supported Protobuf schemas for
SchemaPayloadValidationPolicyPlugin. - Updated the SSL handshake failure logging to include client IP addresses (which were previously missing from error logs), helping you identify applications that are affected by certificate issues.
Improvements v1.36.2
- Added support for SMTPS servers in email alerting to allow TLS-enabled SMTP servers, as well as the previously available option for StartTLS.
Fixes v1.36.2
- Fixed an issue where the Console UI would prevent Debezium connector creation when required metadata was missing, even though the CLI would allow creation successfully.
- Fixed a permissions bug where users who were members of multiple ApplicationGroups would only inherit permissions from one group instead of receiving the combined permissions from all their groups. This was causing users to have incomplete access rights.
- Updated the base image to include upstream patches for CVE-2025-30749, CVE-2025-50059, and CVE-2025-50106 affecting Oracle Java SE and GraalVM.
Fixes v1.36.1
- Fixed an issue where the default produce header used a problematic naming format (app.name) that could cause compatibility issues with certain connectors
- Resolved the known issue from 1.36.0 where Self-service resource policies attached to Self-service application instances would display validation errors on the details page in Console
New features
New features v3.11.0
Set Virtual Cluster ACLs directly using REST
Gateway now supports managing the ACLs for Virtual Clusters directly using the REST API. (This is a backwards compatible change.)Previously, the only way to set ACLs on a Virtual Cluster was to:- create a Virtual Cluster with a Kafka super user defined, then
- as the Kafka super user, individually create ACLs using the Kafka admin API.
Auto-create topics
You can now create topics automatically when producing or consuming through Gateway. To enable/disable this, we’ve added a newGATEWAY_AUTO_CREATE_TOPICS_ENABLED environment variable (default: false).- Kafka property integration: leverages the Kafka property
auto.create.topics.enablewhen the feature is enabled. - Concentrated topics limitation: when this feature is enabled, topics that would normally be concentrated will be created as physical topics instead.
- ACL authorization: implements proper access control for auto-create topics:
- permission requirements: requires
CREATEpermission on either the topic or the cluster. - security: ensures access control while maintaining flexibility for different permission models.
- permission requirements: requires
- Conduktor Scale:
- Conduktor Exchange:
- Quality of life improvements
- Fixes
- Known issue
Conduktor Scale
New alert destination: email
You can now set emails as alert destinations. Set up your SMTP server with TLS encryption and authentication to enable secure email delivery directly to your inbox.Create customized email alerts with custom subjects and body content per alert. Dynamic variables like{{clusterName}} and {{threshold}} can be embedded using handlebars syntax for context-aware notifications that provide meaningful alert details.Find out how to configure email integration.Configurable Webhook body
Webhook alert destinations now support full payload customization. In addition to existing header customizations, you can now secure your webhooks with basic auth or bearer token authentication and customize the body of the webhook payload to be sent when an alert is triggered.Like email alerts, webhook bodies support dynamic variable insertion using handlebars syntax, allowing you to create context-aware webhook payloads tailored to your specific monitoring needs.Redesigned Application Catalog and Application details pages in Console
Application details page:- displays a list of the application instances with labels and stats.
- includes an editor for modifying the application description.
- shows the application groups list with the owner group pinned.
- header section displays stats and labels, with the ability to manage labels.
- contains multiple tabs: Details, External access, Alerts, and API keys.
- within the Details tab, information is divided into two sections: ownership and resource policies.
Labels for Consumer groups
Labels are now shown across various consumer groups views, along with new filtering capabilities:- The consumer groups list now shows labels and allows filtering by them.
- Topic lists within both the consumer groups and member details pages now support label-based filtering.
- In the topic details view for consumer groups, labels are visible and can be added, edited, or deleted.
More information on tasks with errors
A connector that’s in theRUNNING state can also return errors that are only visible within the Confluent Cloud UI. When a connector is in this state:- a warning icon will be shown next to the item in the list view and
- an error returned from the Confluent Cloud API will be displayed.
Conduktor Exchange
Breaking changes - Partner Zones support for mTLS
With support for mTLS connections, Partner Zones now have breaking changes: all existing Partner Zones have to be re-created (even if not using mTLS).Partners can now connect their clients to your Partner Zone using mTLS.This is an additional option ofMTLS for the spec.authenticationMode.type.Find out more about prerequisites for creating Partner Zones.Quality of life improvements v1.36.0
- Users will now be redirected to the page they were on when they logged in again after session expiry.
- Improved navigation between Partner Zones in the list view when using keyboard.
- Improved configurability of circuit breaker behavior for indexed tasks. Each indexed task now includes configurable
sequentialFailureThresholdandblockingDurationparameters, giving administrators fine-grained control over when indexing operations pause due to failures and how long they remain paused before attempting recovery. This provides predictable recovery behavior and prevents extended indexing outages that previously required Console restarts to resolve. Learn more about circuit breaker configuration.
Fixes v1.36.0
- Partner Zones are now created instantly, instead of waiting for the next reconciliation loop to pass. Other updates will continue to sync in line with the reconciliation loop.
- Fixed an error that occurred when no partitions were selected in the topic consume view. You will now see a warning that no messages will be shown, if partitions filter is set to none.
- The JSON view of a message in a topic now correctly displays negative numbers and numbers in scientific notation.
- Kafka Connect clusters are no longer visible to users who don’t have the permission on any of their connectors.
- Error messages are now more informative when attempting to create a service account on a resource for which the caller lacks permission.
- Resolved a case sensitivity issue with email addresses in the application group payload that caused mismatch in the RBAC configuration.
Known issue v1.36.0
If a Self-service resource policy is attached to a Self-service application instance, the details page for it may display a validation error in Console.Fixes
- Fixed an issue introduced in
v0.6.0, where intermittent failure on some apply runs where kind ordering would not be respected. In some scenarios the parent resource is not made before the child (e.g. ApplicationInstances being created before Applications) and the run would fail, this could be fixed by attempting a retry. - Fixed an issue introduced in
v0.6.0where failed runs would not return an exit code, leading to silent failures in CI actions.
Changes
This release introduced a couple of bugs that were fixed in CLI v0.6.1, please use that version instead of v0.6.0.
apply operations, use the --parallelism flag.The flag accepts integer values between 1 and 100. If a value outside this range is provided, the command will show an error and exit. Find out more.Change
- The -o flags are now visible at the get root command level, making output options more discoverable.
Fix
- Fixed an issue where alerts could not be deleted via the CLI when using the metadata group. Find out more.
Changes
- Included Gateway resources in
get all - Added cause to ApiError responses
- Fixed apply template comment in YAML file
- Added option to edit and apply immediately to template command
- Standardized flag descriptions
Fix
- Fixed verbose mode in single client configuration
Changes
- Environment variable references can now be passed to Gateway or Console, allowing you to store references to secret variables used by the host within your configuration.
- Partner Zones are now available, allowing you to securely share your streaming Kafka data with external partners without the need to replicate the data.
- More informative error responses in certain situations
- Console API schema updated
- Added
run - Schema code reorg
- Ops 630 pass external environment variable reference
- Introduced dev mode for hidden command
- Panic replaced with graceful exit
- Included Partner Zones Gateway API changes
Fixes
- buildAlias duplication fixed
- Fixed ServiceAccount check when defining commands
- Release Action fixed
- Various doc fixes
- Fixed duplicate printout statements
Changes
- Added support for
-o jsonand-o nameonget - Updated to latest Gateway API
- Added support for Gateway API v2
- Clarified version with a
v
Fixes
- Fixed the release tag
- Fixed missing key retrieval from environment
Changes
- Made
/apinot mandatory when setting base URL - Updated offline schema for future
- Added support for description from file in topic resources
- Added support for
delete -f - Improved client interface
- Improved CLI API for terraform provider POC
- Added a command to create token
- Added a login command
Fix
- Fixed auto login in client
Changes
- Started with v to solve issue with go package
- Use resource priority from default catalog if catalog doesn’t have any
- Added resource priority
- Keep order from API response
- Updated offline kind
Breaking changes
- CDK_TOKEN is now CDK_API_KEY
- automation update brew formula
- improved docs
Features
- This release is only compatible with Console 1.23 or above
- Made CTL work with complex path
- Set CDK-CLIENT header to improve analytics
Fixes
- Fix for adding
prefix X-to custom header
Features
- Add uniform CLI help commands/flags descriptions
- Use alpine as base Docker image with custom user
- Added support for multiple failing apply to get a detailed summary
Conduktor CLI allows you to perform operations directly from your command line or a CI/CD pipeline to a Conduktor Console instance.
Features
- Support for
get,apply(upsert) anddeletecommands for the following Conduktor Console resources:- Application
- ApplicationInstance
- ApplicationInstancePermission
- Support for
--dry-runonapplyanddelete - Support
completionthat generates the autocompletion script for the specified shell - Support for proxy auth using certificate and key
- Support
ignoreuntrusted certificates environment variable - Configurable environment variables