Overview
Preview functionality
This is currently a Preview feature and is subject to change as we continue working on it.
- Querying Kafka message data
- Querying Kafka metadata (such as the offset, partition and timestamp)
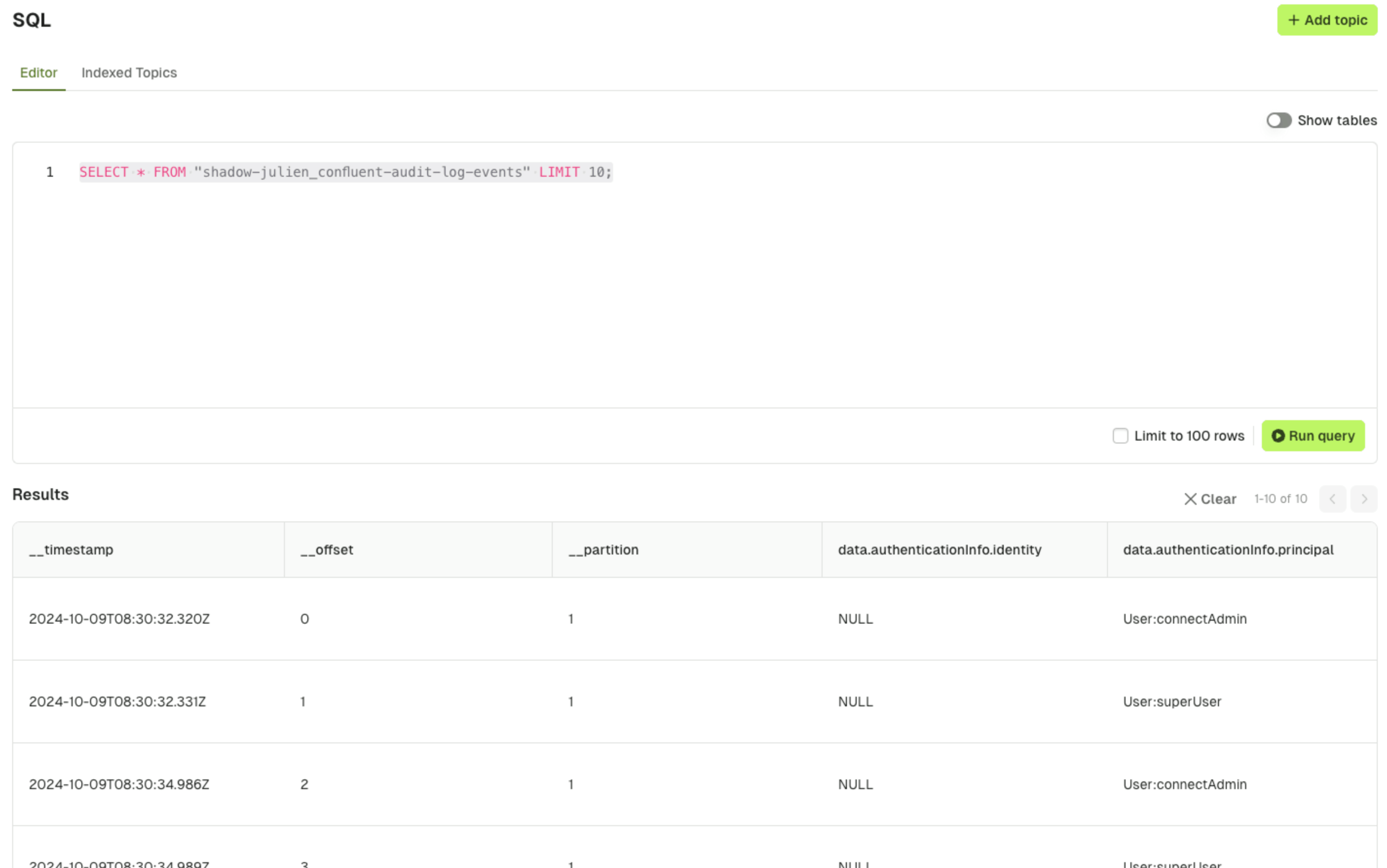
Console configuration
For a fully integrated Docker Compose, run our get started stack to try SQL. The below guide details how to add this feature to your existing deployment.Database configuration
By default, the SQL feature is disabled. You will need to add additional configuration about the database for storing the data. Configure the second database through environment variables:CDK_KAFKASQL_DATABASE_URL: database connection URL in the format[jdbc:]postgresql://[user[:password]@]netloc[:port][/dbname][?param1=value1&...]. If you don’t have this set, SQL will not appear in the sidebar.
CDK_KAFKASQL_DATABASE_HOST: Postgresql server host nameCDK_KAFKASQL_DATABASE_PORT: Postgresql server portCDK_KAFKASQL_DATABASE_NAME: Database nameCDK_KAFKASQL_DATABASE_USERNAME: Database login roleCDK_KAFKASQL_DATABASE_PASSWORD: Database login passwordCDK_KAFKASQL_DATABASE_CONNECTIONTIMEOUT: Connection timeout option in seconds
Additional configuration
Note that additional configuration can be made in relation to the indexing process:CDK_KAFKASQL_CONSUMER-GROUP-ID: Consumer group name for the indexing process (default isconduktor-sql)CDK_KAFKASQL_CLEAN-EXPIRED-RECORD-EVERY-IN-HOUR: The interval in which the clean-up process will run to purge data outside the desired retention periodCDK_KAFKA_SQL_REFRESH-TOPIC-CONFIGURATION-EVERY-IN-SEC: Time interval before taking into account anysqlStorageconfiguration changes on Topic resourcesCDK_KAFKASQL_REFRESH-USER-PERMISSIONS-EVERY-IN-SEC: See RBAC
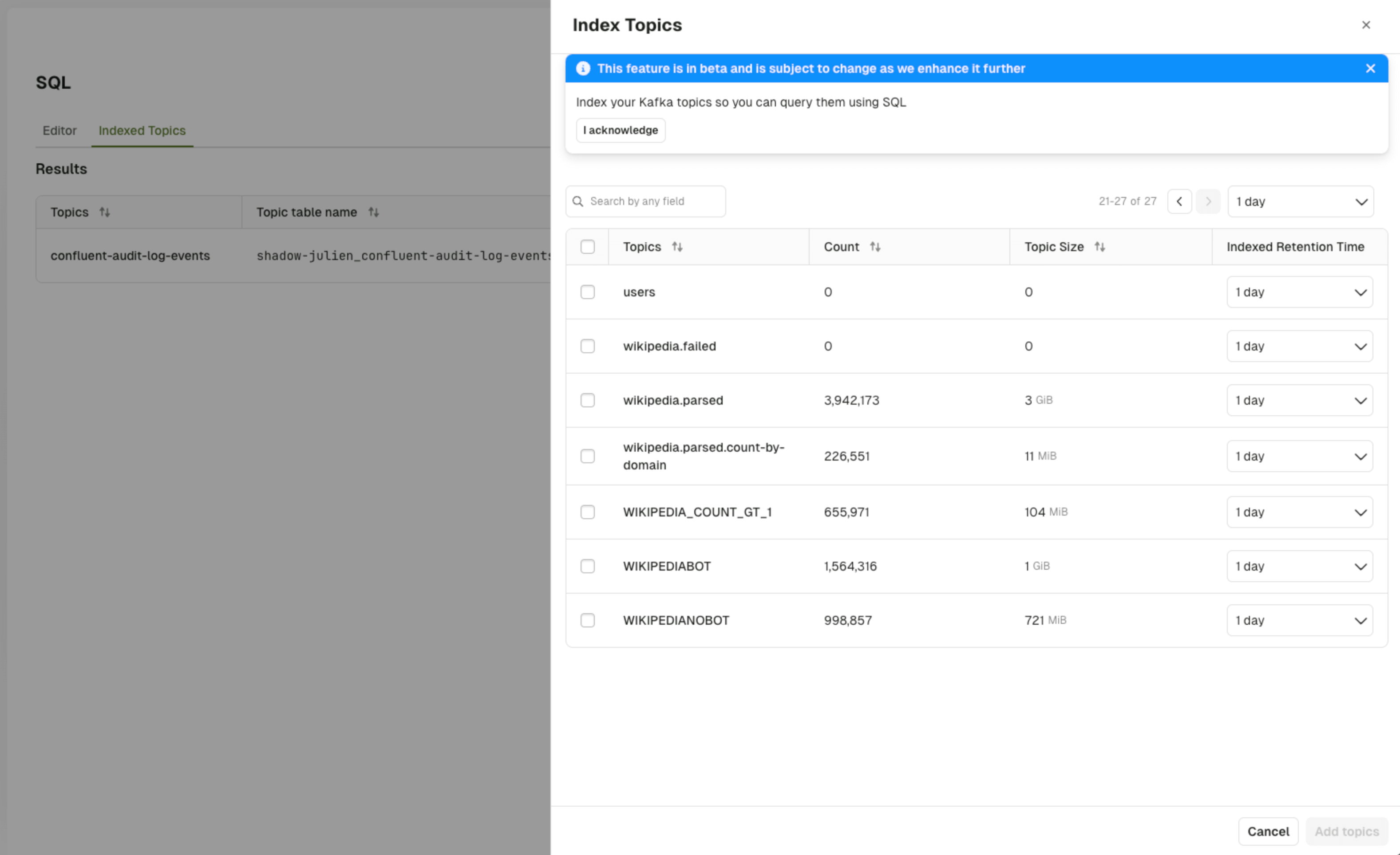
Index topics for querying
Index topics in the UI
To create a new indexed topic, you can use the UI by navigating to the new SQL tab. Note you will only see this tab if you have configured the SQL database as a dependency. Currently, only Admins have thekafka.topics.config.sql permission required to opt topics in for indexing. This permission is verified whenever a user attempts to update the sqlStorage configuration for a topic.
When selecting a topic for indexing, you will be asked to configure the:
- Indexed Retention Time: The furthest point in time from which the data will be indexed. Note that any data before this point in time will be purged periodically.
- By default, purging happens every 1h, but it’s configurable using the environment variable
CDK_KAFKASQL_CLEAN-EXPIRED-RECORD-EVERY-IN-HOUR
- By default, purging happens every 1h, but it’s configurable using the environment variable
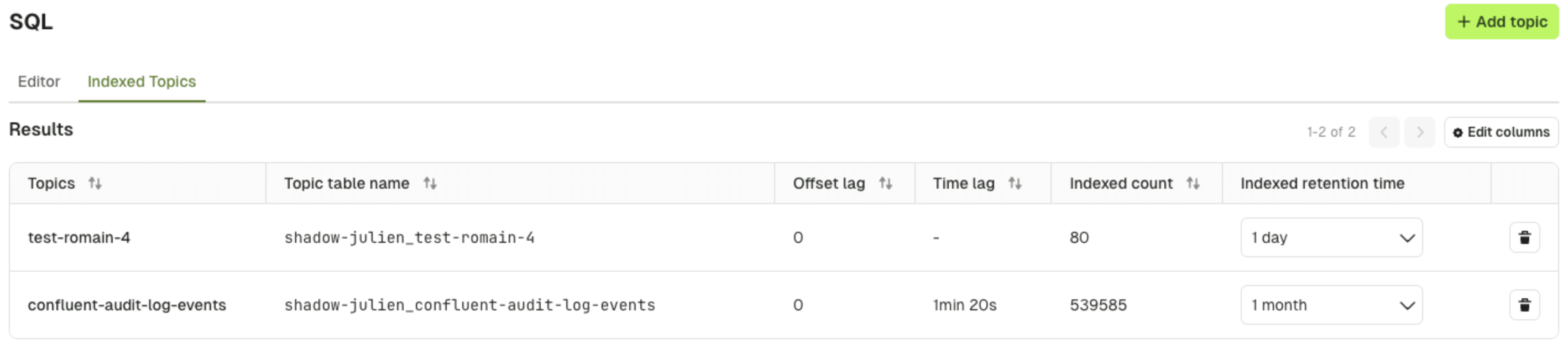
- Offset lag: The difference between the latest message offset in the Kafka topic and the current offset of the consumer group, indicating how much data is yet to be processed
- Time lag: The delay between the timestamp of the latest message in the Kafka topic and the time when the message was indexed, reflecting processing latency
- Indexed count: The total number of messages successfully indexed into the database table from the Kafka topic
Index Topics in the CLI
Alternatively, you can index a topic through the conduktor CLI:Querying the data
Using the UIQuery syntax requires the cluster technical-id is used as a prefix for the table name e.g. for the topic
customers on the cluster kafka-cluster-dev:
Database storage format
Each indexed topic will have its dedicated SQL table. The table’s name will apply the following convention${cluster-technical-id}_${topic-name}.
The table will contain special column types, each of those columns is indexed:
__timestamp__partition__offset__checksum: the checksum of the tuple (message(s) key, message(s) value)__headers: the message(s) headers__schema_id: the schema id__key: the message(s) key
If records with a different shape come later, the table schema will be updated:
If a record contains array, then the cardinality is too high and so we don’t flatten the structure. Instead we create a JSON column containing the array content:
Shrinker
As column names are limited in size (63 characters), the field name must sometimes be shrunk. We try to do that intelligently so it is still meaningful for users. The head characters are removed first:my.reaaaally.loooooooooooooooooooooooooooooong.path.to.a.field
will give
m.r.oong.path.to.a.field
Collision Solver
Sometimes, the table or column names can be the same for two different topics or fields. To resolve the conflict, we suffix the name by_${inc} (e.g. my.field & my.field_2).
Relation between a table/column and a topic/field is tracked in special metadata tables:
_table_mappings_table_fields_mappings
Database isolation
The Kafka SQL feature, while providing flexibility, introduces potential security risks. By allowing users (only admin) to execute arbitrary SQL commands, there’s a chance of unauthorized access or malicious activities. To mitigate these risks, we’ve implemented several security measures.- Read-only connections: while not foolproof, enforcing read-only connections limits the potential for data modification
- SQL query pre-parsing and sanitizing:
- Schema restriction: restricting queries to the public schema prevents access to sensitive data in other schemas. For example, in the Conduktor database, the public schema is empty (except for the Flyway migration table which is also hidden)
- Query type limitation: allowing only SELECT statements ensures that users cannot modify or delete data. For example, it forbids ROLLBACK which would break the previous limitation
- Resource contention: prevents the Kafka indexing process or a user’s arbitrary request from consuming excessive resources and impacting the overall system performance
- Data breach mitigation: limits the potential damage in case of a security breach in the SQL endpoint protection (not totally foolproof).
SQL security
Conduktor’s RBAC model and data masking capabilities are applicable when using SQL.RBAC
The Console RBAC model is integrated with the PostgreSQL database using PostgreSQL’s built-in ROLE feature. There are two distinct processes involved:-
Initial role creation: when a user executes a SQL query on Console for the first time, the system checks if the corresponding user ROLE exists in the PostgreSQL database. If it does not, the RBAC system is consulted to determine the topics for which the user has the
kafka.topics.readpermission. The user’s ROLE is then created in PostgreSQL, and read access to the relevant topic tables is granted. -
Periodic role updates: a background process in the Console periodically updates the access rights for each user ROLE to ensure they remain aligned with the RBAC permissions. The job is run every 30 seconds by default and can be customized by setting the env variable
CDK_KAFKASQL_REFRESHUSERPERMISSIONSEVERYINSEC.
Data masking
Data masking policies are implemented similarly to RBAC. By default, access is granted to all columns in a table. However, if a data masking policy applies to a specific column for a given user, access to that column is denied. There are some limitations:- Instead of applying the masking policy as defined in Console, access to the entire column is restricted for simplicity
- For JSON blob columns, we are unable to restrict access to sub-objects, so access to the entire column content is restricted instead
- If access to a column is denied, the user cannot use a wildcard in a
SELECTquery (e.g.,SELECT * FROM table). Attempting to do so will result in an access denied error
UI Experience
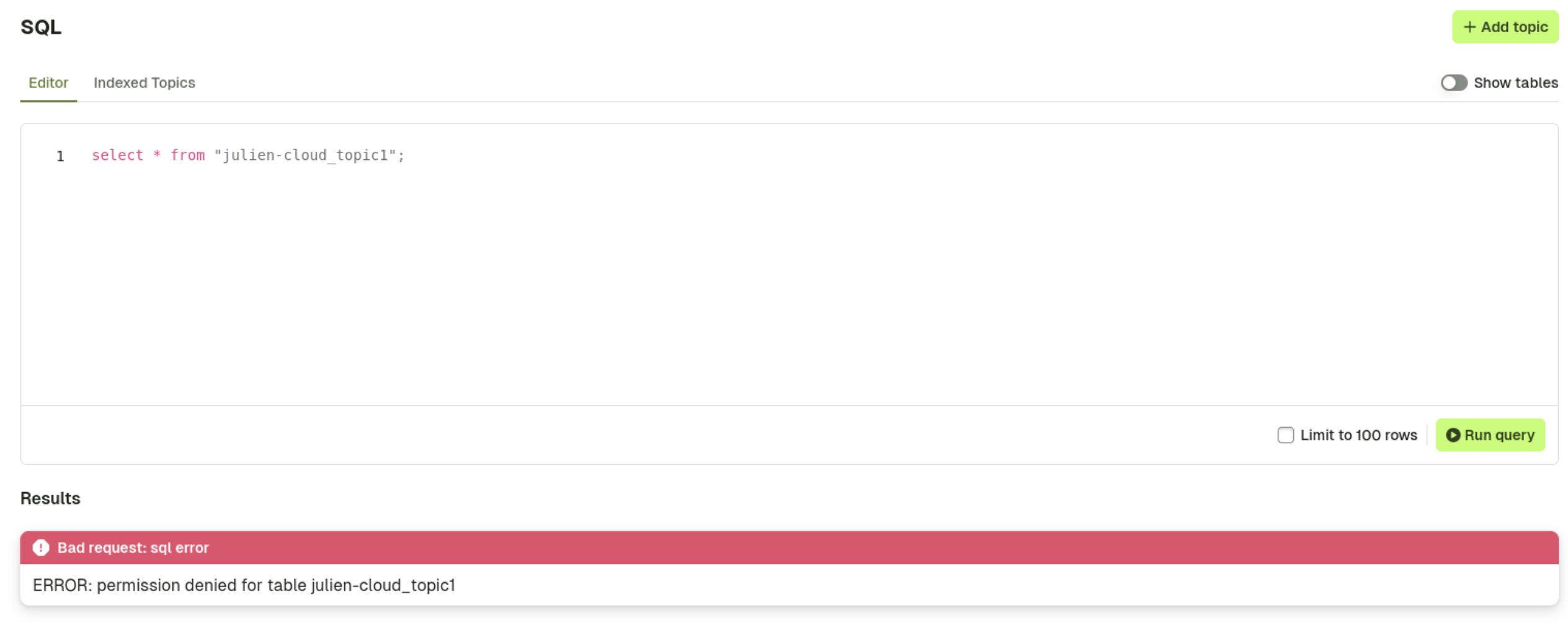
The user will only see the table(s) and field(s) they have access to on the UI: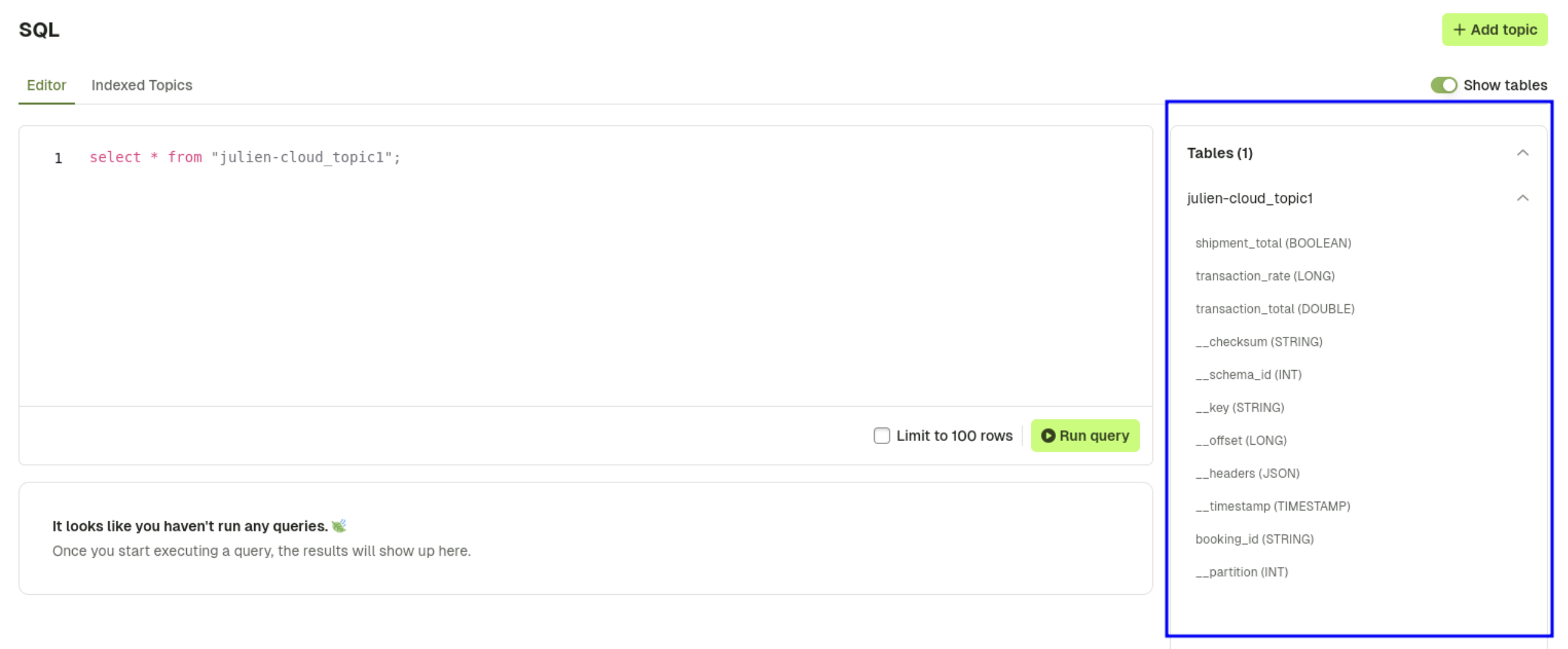
Known limitations
There are several known limitations with the current preview experience:- Data formats currently supported are plain
JSON, and bothAvro&JSONwith Confluent schema registry - If for any reason a record can’t be parsed, they are ignored and the consumer continues
- To efficiently import data in Postgres, we didn’t set any primary key, so a record can be there more than once
- If you try to index a topic with a schema that is not supported, the lag value will be 0 but no records will appear in the table
- Admin API tokens are not supported with the Conduktor CLI. To execute SQL using the CLI, please utilize the user password authentication method, or short-lived user token.