- Gateway internal load balancing or
- an external load balancing
Internal load balancing
Gateway’s ability to distribute the client connections between the different Gateway nodes in the same cluster is what we refer to as internal load balancing. This is done automatically by Gateway and is the default behavior. To deploy multiple Gateway nodes as part of the same Gateway cluster, you have to set the sameGATEWAY_CLUSTER_ID in each node’s deployment configuration. This configuration ensures that all nodes join the same consumer group, enabling them to consume an internal topic from your Kafka cluster. This is how the nodes recognize each other as members of the same Gateway cluster.
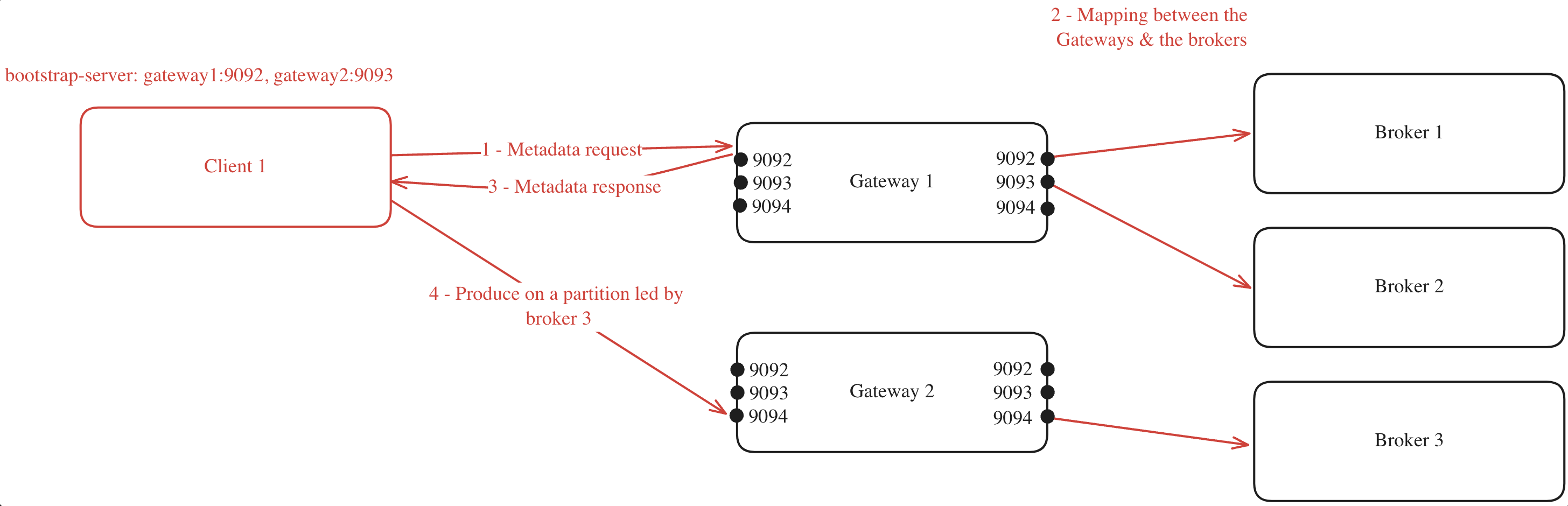
When a client connects to one of the Gateway nodes to request metadata, the following process occurs (assuming GATEWAY_FEATURE_FLAGS_INTERNAL_LOAD_BALANCING is set to true, which is the default setting):
- The client chooses one of the bootstrap servers to ask for metadata.
- The Gateway node generates a mapping between its cluster nodes and the Kafka brokers.
- The Gateway node returns this mapping to the client.
- With the mapping in hand, the client can efficiently route its requests. For instance, if the client needs to produce to a partition where broker 3 is the leader, it knows to forward the request to Gateway 2 on port 9094.
If you have specified a
GATEWAY_RACK_ID, then the mapping will take this into consideration and a Gateway node in the same rack as the Kafka broker will be assigned.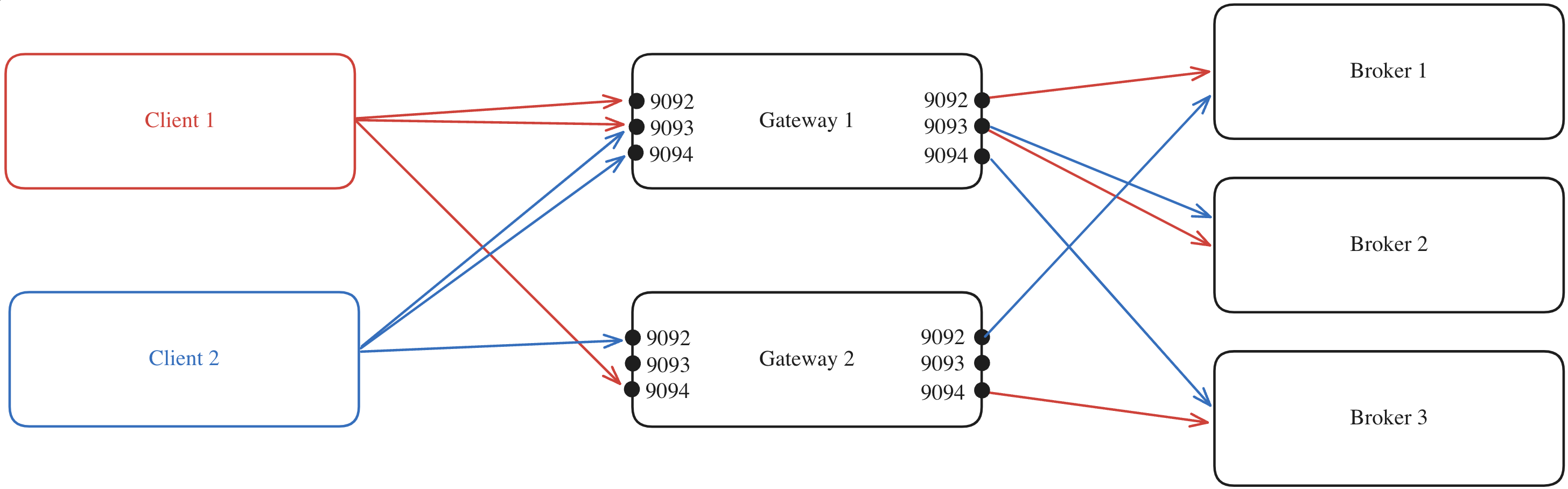
Internal load balancing limitations
In a Kubernetes environment, your ingress must point at a single service, which could be an external load balancer as detailed below.External load balancing
Alternatively, you can disable the internal load balancing by settingGATEWAY_FEATURE_FLAGS_INTERNAL_LOAD_BALANCING: false.
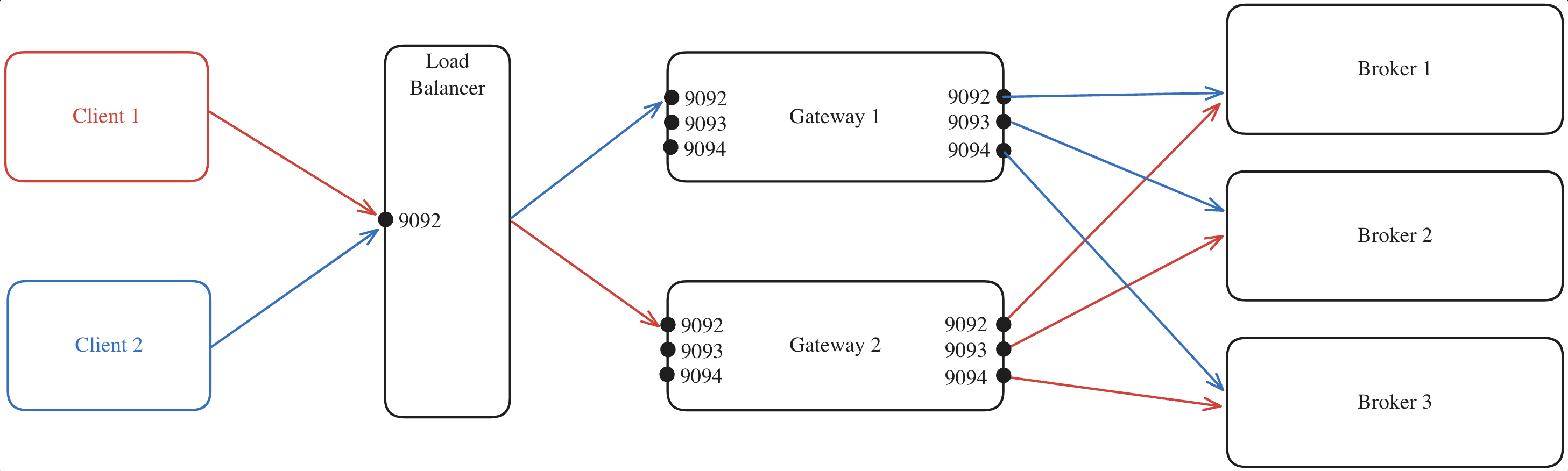
Here’s an example where:
- All client requests are directed to the external load balancer which acts as the entry point to your Gateway cluster.
- The load balancer forwards each request to one of the Gateway nodes, regardless of the port.
- The selected Gateway node, which knows which broker is the leader of each partition, forwards the request to the appropriate Kafka broker.
The advertised host is set per listener from Gateway 3.20.0. On earlier versions, the global
GATEWAY_ADVERTISED_HOST serves the same purpose — see Legacy network configuration.Capturing the client IP address
This section only applies if you configure external load balancer yourself, whether a HA Proxy or an AWS load balancer. If your external load balancer is configured by Kubernetes service, see preserving client IP address in the Kubernetes section. When running Conduktor Gateway behind an external load balancer, the load balancer replaces the client IP address with its own, therefore audit log and error messages do not report the actual client IP address. This makes it difficult to identify the actual client IP address if there is an issue, for example, when a client fails during SSL handshake. In order to capture the original client IP address behind an external load balancer, Conduktor Gateway supports HAProxy Protocol. To enable HAProxy Protocol support, setGATEWAY_FEATURE_FLAGS_HAPROXY_PROTOCOL to true. At the same time, you must also configure the external load balancer to send HAProxy Protocol header to Conduktor Gateway.
If HAProxy Protocol is enabled, Conduktor Gateway reads the client IP address from the HAProxy Protocol header then add it to CONNECTION audit log entry as proxySourceAddress and proxyDestinationAddress. The connection error messages will also include (original source: [IP:PORT], original destination: [IP:PORT]).
For reference, this is the external documentation on enabling HAProxy Protocol header:
External load balancing limitations
This requires you to handle load balancing manually, as you won’t have the advantage of the automatic load balancing offered by Gateway’s internal load balancing feature.Is Gateway a single point of failure?
Is Gateway a single point of failure?
No. Gateway is not a Single Point of Failure (SPOF).It works the same way that Kafka does: deploy many instances, spread the load, restart them - clients continue without impact.StatelessGateway doesn’t store local data, so a restart never affects traffic. The backing Kafka cluster stores all the states.Kafka-awareClients use their normal retry and metadata refresh flows (same as with brokers). When a Gateway instance becomes unavailable, clients re-connect to another instance using standard Kafka client behavior.Scale horizontallyRun several pods to handle load and keep latency steady. You can add or remove instances based on throughput needs as Gateway scales horizontally.Safe restartsRoll restart any pod and clients re-connect on their own. Standard Kafka client retry mechanisms handle temporary unavailability, which makes Gateway restarts transparent to applications.
For production deployments, we recommend at least three Gateway instances to ensure an effective load distribution handling and availability during restarts.