Learn about Kafka’s new consensus protocol in eight minutes KRaft (Kafka Raft) mode is Kafka’s built-in consensus protocol that replaces ZooKeeper for cluster coordination. This architectural change simplifies Kafka deployments and enables better scalability. What you’ll learn:Documentation Index
Fetch the complete documentation index at: https://docs.conduktor.io/llms.txt
Use this file to discover all available pages before exploring further.
- Why ZooKeeper is being removed from Kafka
- How KRaft mode works
- Benefits of running Kafka without ZooKeeper
- When to use KRaft mode
Why remove ZooKeeper from Kafka?
The Kafka project undertook one of its greatest changes with the introduction of KIP-500 on August 1st 2019: the desire to remove ZooKeeper as a dependency to running Apache Kafka. Kafka scaling has hit a performance bottleneck with ZooKeeper, which means Kafka has the following limitations with ZooKeeper:- Kafka clusters only support a limited number of partitions (up to 200,000)
- When a Kafka broker joins or leaves a cluster, a high number of leader elections have to happen which can overload ZooKeeper and slow down the cluster temporarily
- Kafka clusters setup is difficult and depends on another component to setup
- Kafka cluster metadata is sometimes out-of-sync from ZooKeeper
- ZooKeeper security is lagging behind Kafka security
Kafka KRaft mode
It has been noted as part of KIP-500 that the metadata of Kafka itself is a log and that Kafka brokers should be able to consume that metadata log as an internal metadata topic. Kafka leverages itself! Removing ZooKeeper means that Kafka has to still act as a quorum to perform controller election and therefore the Kafka brokers implement the Raft protocol thus giving the name KRaft to the new Kafka Metadata Quorum mode.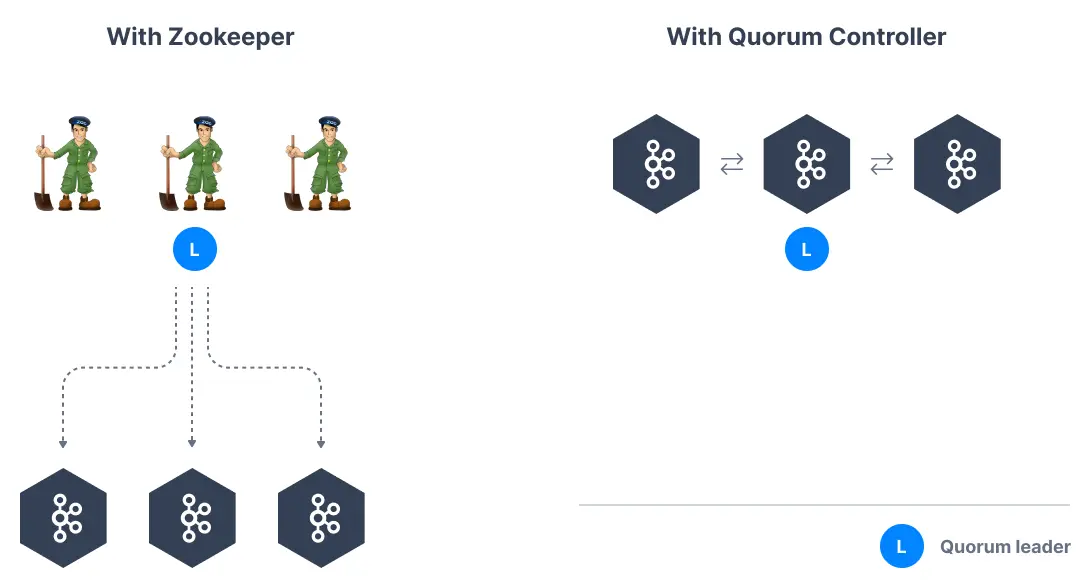
Architecture comparison
Benefits of KRaft mode
Without ZooKeeper, the following benefits are observed in Kafka:| Benefit | Description |
|---|---|
| Scale | Ability to scale to millions of partitions |
| Simplicity | Single process to start Kafka, easier to maintain and set up |
| Stability | Improved stability, easier to monitor, support, and administer |
| Security | Single security model for the whole system |
| Performance | Faster controller shutdown and recovery time |
KRaft deployment modes
KRaft supports two deployment modes:Combined mode
Controllers and brokers run in the same process. Best for:- Development environments
- Small clusters (3-5 nodes)
- Simplified operations
Isolated mode
Controllers and brokers run as separate processes. Best for:- Production environments
- Large clusters
- Maximum stability
Migration considerations
| Current setup | Recommendation |
|---|---|
| New cluster | Use KRaft mode |
| Kafka 2.x | Upgrade to 3.x, then migrate to KRaft |
| Kafka 3.x with ZooKeeper | Migrate to KRaft using official migration tools |
| Kafka 4.x | ZooKeeper not supported, must use KRaft |
More KRaft resources
See it in practice with ConduktorConduktor Console supports both ZooKeeper-based and KRaft-based Kafka clusters. Monitor controller status, metadata synchronization, and cluster health regardless of your deployment mode.