Learn how to tune Kafka consumer settings for optimal performance in 12 minutes Kafka consumers use sophisticated polling and heartbeat mechanisms to efficiently fetch data while maintaining group membership. Understanding these settings is essential for building high-performance, reliable consumer applications. What you’ll learn:Documentation Index
Fetch the complete documentation index at: https://docs.conduktor.io/llms.txt
Use this file to discover all available pages before exploring further.
- How the consumer poll loop works internally
- The relationship between heartbeat and poll threads
- Key configuration settings and their impact
- How to tune for throughput vs latency
Consumer poll behavior
Kafka consumers poll the Kafka broker to receive batches of data. Once the consumer is subscribed to Kafka topics, the poll loop handles all details of coordination, partition rebalances, heartbeats, and data fetching, leaving the developer with a clean API that simply returns available data from assigned partitions.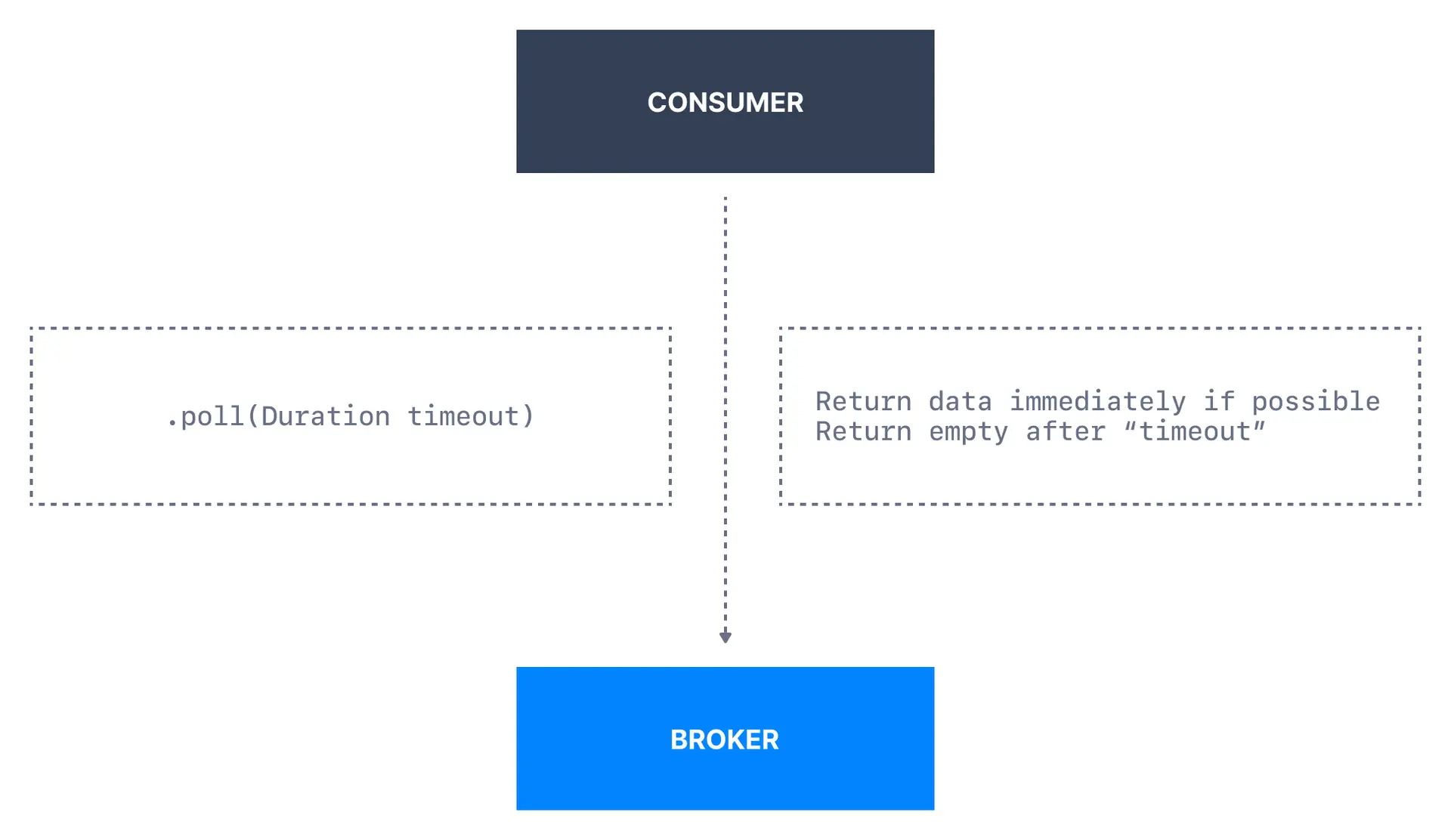
- From where in the log they want to consume
- How fast they want to consume
- Ability to replay events
Internal poll thread and heartbeat thread
The way consumers maintain membership in a consumer group and ownership of partitions is by sendingheartbeats to a Kafka broker designated as the group coordinator.
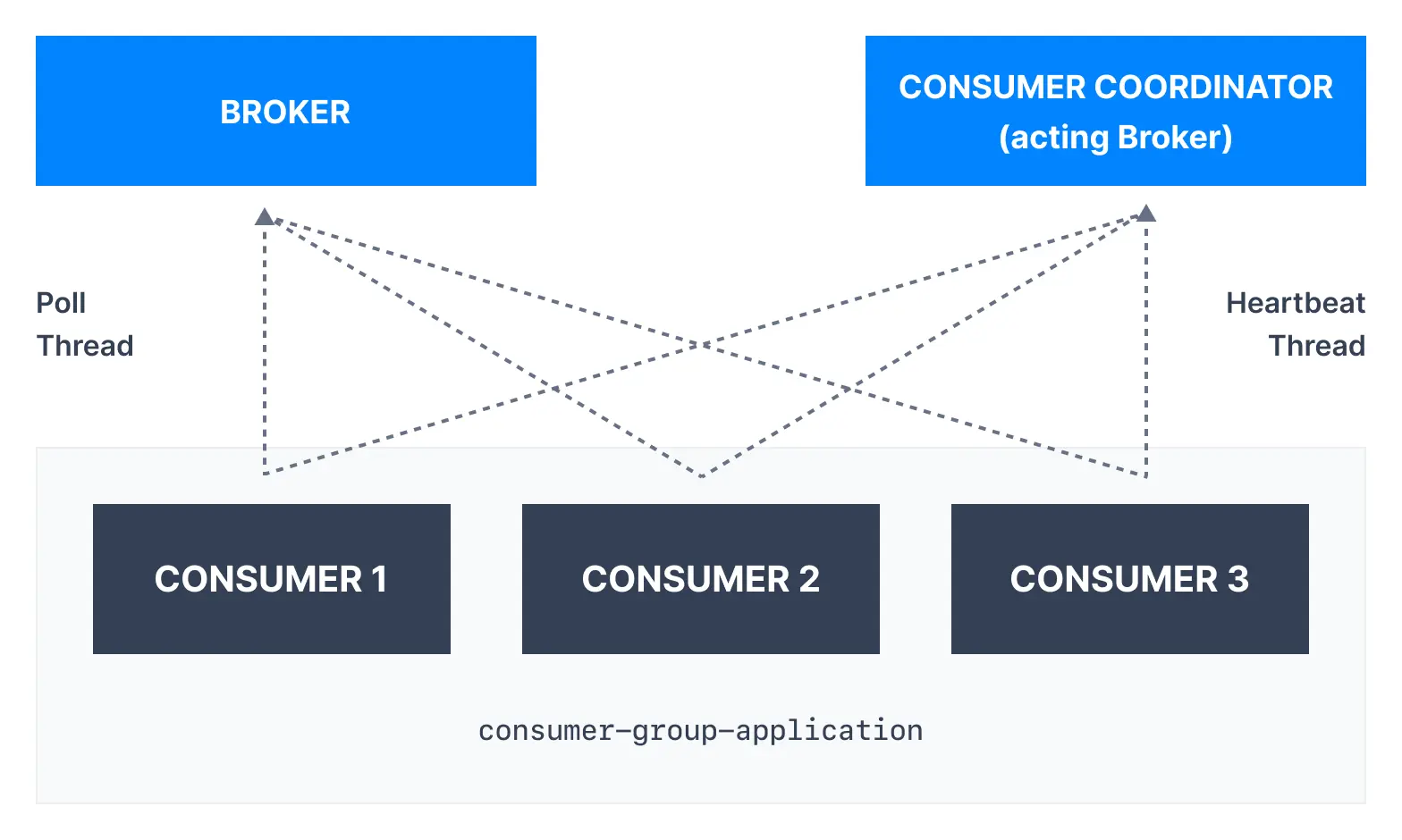
Kafka consumer heartbeat thread
Heartbeats help to determine consumer liveliness:- As long as the consumer sends heartbeats at regular intervals, it is assumed to be alive and processing messages
- If the consumer stops sending heartbeats long enough, its session will time out and trigger a rebalance
heartbeat.interval.ms(default: 3 seconds)session.timeout.ms(Kafka v3.0+: 45 seconds)
Kafka consumer poll thread
Consumers poll brokers periodically using the.poll() method.
Key configuration:
max.poll.interval.ms(default: 5 minutes)
poll(). If this interval is exceeded, the consumer is considered failed and triggers a rebalance.
Important consumer settings
Poll behavior settings
| Setting | Default | Description |
|---|---|---|
max.poll.records | 500 | Maximum records returned in single poll() |
fetch.min.bytes | 1 | Minimum data to return for a fetch request |
fetch.max.wait.ms | 500ms | Maximum wait time if insufficient data |
- Lower values can improve latency but may reduce throughput
- Higher values improve throughput but may increase processing time per batch
- Setting higher values can improve throughput by reducing request overhead
- May increase latency as consumer waits for more data
Session and heartbeat settings
| Setting | Default (Kafka 3.0+) | Description |
|---|---|---|
session.timeout.ms | 45 seconds | Timeout for detecting consumer failures |
heartbeat.interval.ms | 3 seconds | Expected time between heartbeats |
max.poll.interval.ms | 5 minutes | Maximum delay between poll() calls |
Performance tuning guidelines
For high throughput
For low latency
For long processing times
Decision tree
Best practices
- Tune
max.poll.recordsbased on your processing time per message - Set
max.poll.interval.mshigher than your worst-case processing time - Monitor consumer lag to ensure settings are appropriate
- Test rebalance behavior under your expected load conditions
- Consider batch processing patterns when setting poll configurations
Common anti-patterns
| Anti-pattern | Problem | Solution |
|---|---|---|
| Blocking in poll loop | Triggers rebalance | Use async processing |
max.poll.interval.ms too low | Constant rebalances | Increase or reduce batch size |
| Ignoring heartbeat settings | Slow failure detection | Tune for your SLAs |
| Same config for all consumers | Suboptimal performance | Tune per use case |
See it in practice with ConduktorConduktor Console displays real-time consumer lag and rebalance events. Monitor how your configuration changes affect consumer performance and identify optimal settings for your workload.
Next steps
- Configure auto offset reset for new consumers
- Understand delivery semantics for reliable processing
- Implement incremental rebalancing to reduce disruption