Free ebook: Where Kafka costs hide: a field guide Where Kafka spend actually accumulates, and how to find and cut it.
Overview
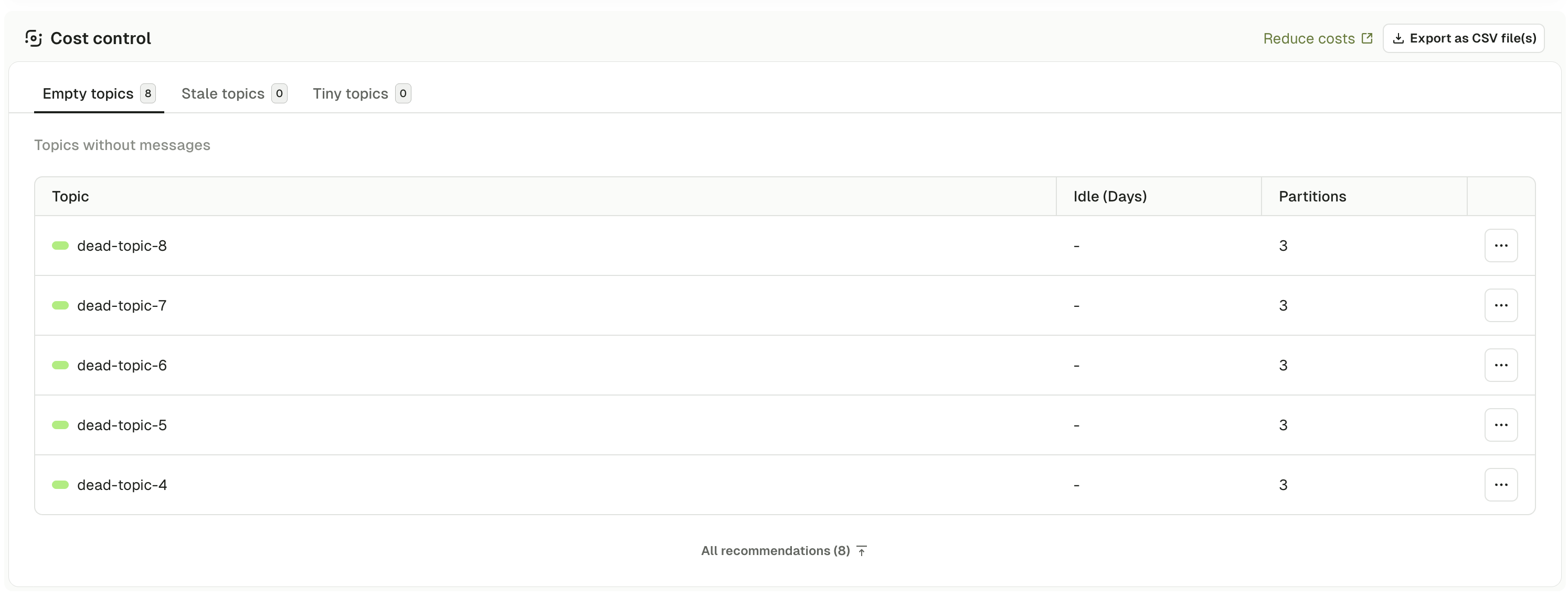
The Cost Control section displays three categories of topics that may be wasting storage:- Empty topics - topics with no messages that consume metadata overhead
- Stale topics - topics with no writes in a configured time period (default: 7+ days)
- Tiny topics - topics with minimal data volume relative to their partition overhead
What the dashboard shows
Empty topics
Topics containing zero messages. These topics have been created but never received data, or have had all messages deleted through retention policies. For each topic: name, idle time in days, and partition count. Empty topics consume cluster resources even without data: metadata storage in ZooKeeper or KRaft, memory for buffers, and often per-partition charges on cloud Kafka services.Empty topics are common in development and staging environments where topics are created for testing but not cleaned up afterward.
Delete an empty topic
Delete an empty topic
Good candidates for deletion:
- topics created for abandoned projects or experiments
- temporary topics used for testing or debugging
- topics created by mistake with typos in the name
- legacy topics from deprecated applications
- topics created automatically by frameworks but never used
- topics pre-created for upcoming features or applications
- topics serving as placeholders for future data pipelines
- topics referenced in consumer group configurations awaiting data
- topics used as dead letter queues that only receive messages in error scenarios
1
Verify the topic is unused
Click the topic name to go to the Topics page. Check:
- Consumer Groups tab for active consumers or unconsumed data (lag > 0)
- Monitoring tab graphs to confirm zero produce activity
- Application references in codebases and deployment configs
- Dependencies - verify no streaming jobs or external systems depend on the topic
2
Delete from the list
In the Cost Control section, click the … menu next to the topic and select Delete topic.
3
Confirm deletion
Type DELETE to confirm and click the delete button.
Topic deletion can take up to 5 minutes to be reflected in the dashboard. Consumer groups that were subscribed will need to be updated to remove the topic from their subscriptions.
Stale topics
Topics with no write activity for 7+ days and no active consumer groups. For each topic: name, idle time in days, and partition count. Stale topics often indicate abandoned data pipelines from shut down applications, failed producers or cancelled projects. They continue consuming storage through retention policies and add operational overhead.Evaluate and handle stale topics
Evaluate and handle stale topics
Investigation checklist:
- Check consumer groups - Are any consumers actively reading from the topic?
- Review consumer lag - Is there unconsumed data that applications still need?
- Verify business requirements - Is the historical data needed for compliance or analytics?
- Contact topic owners - Do the application teams still need this topic?
- Check data lineage - Do downstream systems depend on this data?
- No active consumer groups subscribed
- All consumers show zero lag (all data has been consumed)
- Application owners confirm the topic is no longer needed
- No compliance requirements for data retention
- Historical data has been archived to long-term storage
- Active consumers are still reading historical data
- Data is required for compliance or audit purposes
- Topic serves as a source of truth for event sourcing
- Downstream analytics or reporting systems depend on the data
- Occasional writes expected (seasonal or infrequent events)
Archive stale topic data before deletion
Archive stale topic data before deletion
For topics containing valuable historical data, export and archive the data before deletion.
1
Export the topic data
Navigate to the topic, click the Consume tab, configure the consumer to read from Beginning offset, and export data to a file or external storage.
For large topics, use a dedicated archival tool or Kafka Connect to export data to object storage (S3, Azure Blob Storage) or a data lake.
2
Verify the archive
Confirm all messages were exported successfully, validate the data format and completeness, and store in long-term storage with documentation of location and format.
Maintain a record of archived topics including the archive location, date, original message count and retention period for the archived data.
3
Delete the topic
Follow the deletion steps above.
Reduce retention on stale topics
Reduce retention on stale topics
If a topic might receive future writes but historical data is no longer needed, reduce the retention period instead of deleting.
1
Update retention settings
Navigate to Topics, select the topic, click Configuration, and edit:
retention.ms- Time-based retention (e.g.,86400000for 1 day)retention.bytes- Size-based retention per partition (e.g.,1073741824for 1 GB)
Kafka automatically deletes segments older than the retention period during its next cleanup cycle (typically runs every few minutes based on broker configuration).
2
Monitor cleanup
Monitor the topic size in the Overview tab to verify that old data is being cleaned up as expected.
Tiny topics
Topics meeting all of the following: more than 1 partition, less than 10 MB of data OR fewer than 1000 messages, and name does not end with_repartition.
For each topic: name, idle time in days, and partition count.
Topics with many partitions but little data represent inefficient resource allocation. Cloud Kafka services often charge per partition, and high partition counts increase controller overhead.
A common cause is using default partition counts (often 6-12) for topics that only receive occasional messages, such as configuration topics or low-volume event streams.
Optimize tiny topics
Optimize tiny topics
How to evaluate:Keep the topic as-is if it expects significant growth, requires high parallelism, is part of a standardized policy or would require complex migration. Consider optimization if the topic has been tiny for months without growth, has arbitrary partition counts or handles low-frequency data without parallelism requirements.Since Kafka does not support reducing partition count, you have three options:
- Consolidate topics
- Recreate with fewer partitions
- Accept current state
If you have multiple tiny topics serving similar purposes, consolidate them into a single topic with categorization through message headers or keys. This reduces total partition count while maintaining logical separation.Considerations:
- Identify candidates from the same application with similar schemas
- Design consolidated topic structure with category or type fields
- Update producers and consumers accordingly
Our recommendations
Prevent cost control issues through governance and automated ownership tracking rather than manual remediation. Use Self-service for ownership and governance - it brings a GitOps approach to topic lifecycle management where applications represent streaming apps or data pipelines and dictate ownership of Kafka resources. Benefits for cost control:- Automatic ownership tracking - topics created through Self-service have clear ownership from creation
- Policy enforcement - application instance policies can prevent creation of tiny topics by enforcing minimum data volume or maximum partition count requirements
- Naming conventions - policies enforce consistent naming that includes environment and ownership information
- Lifecycle management - clear application ownership reduces abandoned topics through better tracking and accountability
Troubleshoot
Why does an empty topic show recent activity in monitoring?
Why does an empty topic show recent activity in monitoring?
Producer health checks, monitoring systems or automated tests may send periodic messages that are immediately consumed and deleted. Kafka’s log cleaner activity can also appear as writes in some monitoring systems.Check the Messages in per second graph over 7+ days to distinguish sustained activity from sporadic checks. Review the Consume tab to see actual message content.
Can I recover a topic after deletion?
Can I recover a topic after deletion?
No, topic deletion is permanent. All partition data and topic metadata are removed. Consumer group offsets are retained but the topic cannot be recreated with the same history.Always archive important data before deletion. Implement a grace period policy where topics are first marked for deletion (using labels) before actual removal. To recreate a deleted topic, create a new topic with the same name in Console and restore data from archives if available.
How do I identify topics created by internal Kafka processes?
How do I identify topics created by internal Kafka processes?
Kafka creates internal topics automatically:
__consumer_offsets (consumer group offsets), __transaction_state (transactional state), _schemas (Schema Registry metadata) and topics matching .*-changelog or .*-repartition (Kafka Streams internals).Never delete __consumer_offsets or __transaction_state as this causes cluster-wide failures. Only delete Kafka Streams topics when the application is permanently decommissioned and all instances are shut down.Why does reducing retention not free up disk space immediately?
Why does reducing retention not free up disk space immediately?
Kafka’s log cleanup process runs periodically (default: every 5 minutes). Data is deleted at segment boundaries, not individual messages, and the current active segment is never deleted even if older than retention.Wait 15-30 minutes after reducing retention, then check topic size in the Overview tab.
How do I handle topics with unknown ownership?
How do I handle topics with unknown ownership?
Check topic naming patterns, review consumer groups in the Consumer Groups tab, search code repositories and deployment configs for references, and consult internal documentation.If ownership remains unclear, add a
scheduled-for-deletion label with a future date (for example, 30 days) and send announcements asking owners to identify themselves. After the grace period expires with no claims, proceed with deletion.Implement a policy requiring application labels at topic creation time. Use RBAC permissions to enforce labeling as a prerequisite for topic creation.What if a stale topic suddenly receives writes after months of inactivity?
What if a stale topic suddenly receives writes after months of inactivity?
This is normal for seasonal data (holiday sales, tax season), emergency systems (disaster recovery), compliance events (audit logs) or legacy integrations (backup systems).Verify the producer is authorized, add a
usage-pattern: seasonal or usage-pattern: emergency label, and document the activity pattern. Do not delete topics showing this pattern without understanding the business requirement.