From our blog: No Kafka data platform without ownership Why ownership is the foundation of a governed Kafka platform: accountability, autonomy, scale.
Overview
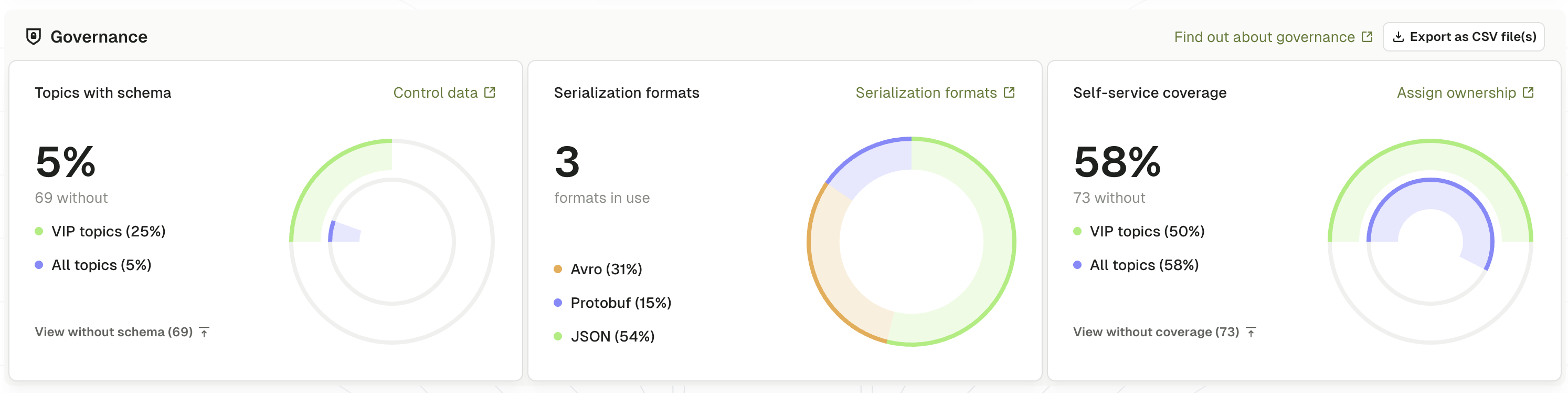
The governance section displays three graphs that measure how well your critical Kafka infrastructure is governed:- Topics with schema: the percentage and count of VIP topics using schema registry for data contracts
- Serialization formats: the distribution of serialization formats in use across VIP topics
- Self-service coverage: the percentage of VIP topics managed through governed Self-service workflows
What the graphs show
Topics with schema
A schema registry enforces data contracts between producers and consumers. Schemas validate data at produce time, rejecting invalid messages before they enter topics. Compatibility modes (backward, forward, full) allow schema evolution without breaking existing consumers. The topics with schema graph shows the percentage of topics that have schemas registered in schema registry:- Percentage of VIP topics with schemas - VIP topics that have registered schemas and enforce data contracts
- Percentage of all topics with schemas - all topics that have registered schemas and enforce data contracts
Clicking a topic type or label in the table applies it as a global filter across all Insights sections.
How to interpret schema coverage
High (80-100%): strong governance with defined data contracts, controlled evolution and established standards Medium (50-79%): partial adoption with gaps in coverage across teams or topic categories Low (<50%): significant gaps with high risk of breaking changes and data quality issuesPrioritize schema adoption for VIP topics first and test in lower environments before deploying to production.
Add schemas to topics
Add schemas to topics
- Register schema in Console - go to Schema Registry and click New Subject. Provide schema definition (Avro, Protobuf or JSON Schema), strategy, and other required settings.
- Update producers - configure Schema Registry URL and use appropriate serializers (KafkaAvroSerializer, KafkaProtobufSerializer or KafkaJsonSchemaSerializer) in producer applications.
-
Verify usage - check the topic’s Overview tab to confirm schema association.
Data is now validated at produce time. Invalid messages are rejected before entering the topic.
create permissions in schema registry.Configure and use schema registrySerialization formats
Using multiple serialization formats increases complexity — each requires different serializers, deserializers, tooling and expertise. Standardizing on one format (or two at most) simplifies operations and makes governance easier to enforce. The serialization formats graph shows the distribution of serialization formats across topics that have schemas registered in schema registry:- Avro - compact binary format with rich schema features
- Protobuf - protocol Buffers format with cross-language support
- JSON schema - JSON with schema validation and documentation
Topics without schemas or using plain JSON/String formats are not shown in this graph.
How to interpret format distribution
Standardized - one dominant format represents 90%+ of schema-registered topics, indicating strong format consistency and simplified operations Mixed - multiple formats each represent significant percentages, suggesting inconsistent practices across teams or ongoing migration effortsHaving multiple formats isn’t necessarily bad but it increases operational complexity.Consider standardizing on one primary format unless there are strong technical reasons to support multiple formats.
Enforce serialization formats
Enforce serialization formats
Conduktor enforces serialization formats using Rules (validation logic) attached to Policies (applied to topics with actions).
-
Create validation Rules - go to Rules under the Trust section and click +New Rule. Choose the appropriate rule type:
- EnforceAvro (built-in) - Ensures messages have a schema ID, the ID exists in Schema Registry, and the schema type is Avro
- JSON schema - Validates JSON messages against a JSON schema definition with required fields and structure
Rules define validation logic but do nothing on their own until attached to a Policy. -
Create and configure Policy - go to Policies under the Trust section and click +New Policy. Attach your Rules, select target topics (specific topics or prefixes like
production-*), and assign to a user group with “Manage data quality” permission. Enable Policy actions based on your governance requirements:- Report - log violations in Policy history for monitoring
- Block - reject non-compliant messages entirely
- Mark - add violation header for downstream handling
- Monitor enforcement - track violations in Policy detail pages and support teams adopting required formats through Schema Registry integration.
Self-service coverage
Self-service workflows enforce organizational standards at topic creation time through templates that mandate naming conventions, required configurations (replication factor, partition count), schema requirements and ownership labels. This provides an audit trail, enables approval workflows and reduces ad-hoc creation that bypasses governance. The Self-service coverage graph shows the percentage of topics managed through governed self-service workflows:- VIP topic Self-service coverage - percentage of business-critical topics under Self-service governance
- Overall Self-service coverage - percentage of all topics created and managed via Self-service
How to interpret Self-service coverage
High (80-100%) - strong adoption with most topics created through proper governance channels Medium (50-79%) - partial adoption, possibly indicating rollout in progress or legacy topics predating self-service Low (<50%) - limited adoption requiring establishment and promotion of workflowsPrioritize Self-service coverage for VIP topics first. Business-critical topics benefit most from governed creation and change management.
Implement Self-service workflows
Implement Self-service workflows
Self-service uses a GitOps approach where platform teams define applications and policies using YAML resources managed through the Conduktor CLI. Application teams then create and manage their own Kafka resources within defined boundaries.
- Define applications and instances - create Application resources representing streaming apps or data pipelines, and ApplicationInstance resources linking each application to specific Kafka clusters with service accounts.
- Establish topic policies - define TopicPolicy resources that enforce standards for resource creation: replication factors, partition limits, retention settings, schema requirements and naming conventions. Create multiple policies for different environments to balance governance with flexibility.
-
Enable application team autonomy - Application teams use the Conduktor CLI with their application context to create Topics, Subjects, Connectors and ApplicationInstancePermissions following defined policies.
Console provides read-only catalog views in Application Catalog and Topic Catalog pages for discoverability.
Teams can now manage their own Kafka resources within governance boundaries and collaborate through permission grants.
Troubleshoot
How do I migrate topics from plain JSON to Avro?
How do I migrate topics from plain JSON to Avro?
Process:
- Design Avro schema matching JSON structure and register in Schema Registry
- Update producers to use KafkaAvroSerializer with Schema Registry URL
- Update consumers to use KafkaAvroDeserializer with Schema Registry URL
- Dual-format (recommended) - Create new Avro topic, write to both topics temporarily, migrate consumers, then decommission old topic
- Big-bang - Schedule downtime, deploy all updates simultaneously with rollback plan ready
What if teams resist adopting self-service workflows?
What if teams resist adopting self-service workflows?
Address common objections:
- Demonstrate self-service is faster than manual ticketing
- Show how templates save time with proven configurations
- Explain governance benefits (reduced errors, better visibility)
- Streamline approval processes to minimize wait times
- Provide excellent documentation and training
- Create templates for common use cases
- Assign self-service champions within teams
- Provide dedicated support during initial adoption
Should 100% of topics have schemas?
Should 100% of topics have schemas?
No, 100% coverage is not necessary. Prioritize schemas for:
- Production topics with business data
- Topics with multiple consumers or teams
- VIP topics with high consumer counts
- Topics requiring data evolution and compatibility
- Configuration or control topics
- Internal framework topics (Kafka Streams, Kafka Connect)
- Development or testing topics
Set realistic targets based on organizational maturity. Focus on production and business-critical topics while allowing pragmatic exceptions.
How do I identify which topics need schemas most urgently?
How do I identify which topics need schemas most urgently?
Highest priority:
- VIP topics without schemas (many consumers, breaking changes affect multiple teams)
- Topics with frequent schema evolution (high risk without compatibility enforcement)
- Topics with multiple producing teams (schema enforces consistency)
- High-throughput topics (debugging costs increase at scale)
- Topics in critical data pipelines (quality issues cascade to business decisions)
- Low-volume internal topics with single consumers