Overview
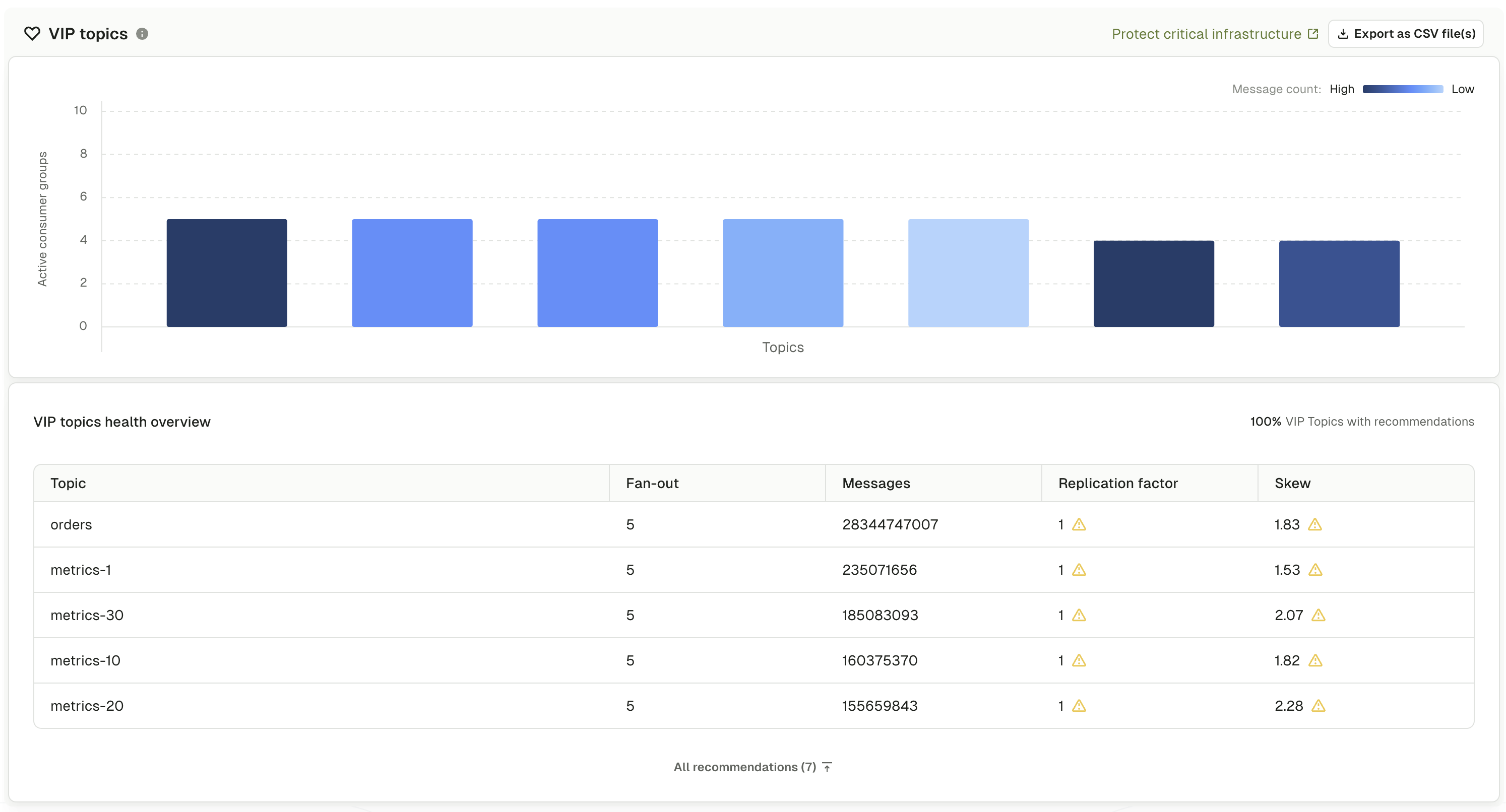
The VIP topics section displays a health overview graph showing topics identified as important to your infrastructure. VIP topics are determined by two key metrics:- Consumer group count - topics with many subscribing consumer groups (shown by bar height)
- Message volume - topics with high throughput and data volume (shown by color intensity)
What the page shows
Firstly, an overview of how well governed the VIP topics are is shown. The bar graph visualizes your most important topics using two dimensions. Bar height represents the number of consumer groups subscribed to each topic:- Taller bars indicate more consumer groups depend on the topic
- Many consumers suggest the topic provides data critical to multiple applications
- Wide usage indicates potential for widespread impact if issues occur
- Darker blue indicates higher message volume and throughput
- Lighter blue indicates lower message volume
- Message volume combined with consumer count identifies truly critical topics
How to interpret the graph
Tall, dark bars - topics with many consumers and high message volume are your most business-critical data pipelines requiring highest priority for monitoring and careful change management. Tall, light bars - topics with many consumers but lower message volume may represent configuration or control topics that still require careful management despite lower throughput. Short, dark bars - topics with high message volume but fewer consumers represent specialized high-throughput pipelines requiring performance optimization and capacity planning.What the table shows
Below the graph, an expandable VIP topic health overview table provides detailed metrics for topics with recommendations. The table header shows the percentage of VIP topics that have recommendations requiring attention.- Topic: topic name with topic type label (internal, streams, or user) and any custom labels
- Fan-out: number of consumer groups subscribed to the topic
- Messages: total message count showing volume
- Replication factor: number of replicas for fault tolerance
- Skew: partition imbalance percentage
Our recommendations
For each VIP topic identified in the dashboard, verify and optimize configurations across multiple areas. Expand each section to review specific actions and guidance.Review topic configuration
Review topic configuration
Navigate to the topic
Open the Configuration tab
Verify critical settings
- Has to be at least 3 for production VIP topics
- Provides fault tolerance for broker failures
- Ensures data durability and availability
- Check the data loss risk graph in risk analysis for topics with insufficient replication
retention.ms- Time-based retention appropriate for business needsretention.bytes- Size-based retention per partition if applicable- Consider longer retention for VIP topics to support late-arriving consumers
- Sufficient partitions for current and projected throughput
- Ideally a multiple of broker count for even distribution
- Adequate parallelism for all consumer groups
delete- For time-series or event datacompact- For state or changelog topics- Appropriate for the data model and consumption patterns
Set up monitoring and alerts
Set up monitoring and alerts
Navigate to the VIP topic
Configure consumer lag alerts
- Define acceptable lag limits based on business requirements
- Use stricter thresholds for VIP topics than standard topics
- Alert on both absolute lag (message count) and time-based lag
Create under-replicated partition alerts
- Alert immediately if any partitions become under-replicated
- Under-replicated partitions indicate broker issues or failures
- Critical for VIP topics where data loss risk is unacceptable
Set disk usage alerts
- Alert on rapid growth that could cause disk space issues
- Track retention effectiveness
- Plan capacity expansions before reaching limits
Configure throughput alerts
- Alert on sudden drops in produce rate (possible producer failure)
- Alert on unexpected spikes that could cause performance issues
- Baseline normal throughput to detect anomalies
Establish ownership and governance
Establish ownership and governance
- Automatic ownership tracking - applications define owners and business context at topic creation
- Clear accountability - Console automatically assigns ownership to application teams
- Governance enforcement - policies ensure VIP topics meet configuration standards (RF=3, appropriate retention)
- Business context preserved - application definitions maintain documentation about purpose, dependencies and SLAs
- When issues occur, the right teams are contacted immediately through defined ownership
- Configuration changes follow approval workflows specific to business-critical topics
- Governance policies prevent VIP topics from being created with suboptimal settings
- Topic purpose and dependencies are documented in application definitions
Review access controls and security
Review access controls and security
Verify RBAC permissions
- Limit producer permissions to authorized applications only
- Restrict consumer access to approved teams and services
- Require elevated permissions for configuration changes
- Audit permissions regularly for VIP topics
Review security policies
- Verify encryption in transit (SSL/TLS) is enforced
- Confirm ACLs or RBAC rules restrict access appropriately
- Check for data masking or encryption requirements
- Ensure compliance with organizational security policies
Monitor consumer health
Monitor consumer health
Navigate to the VIP topic
Review consumer group metrics
- Lag - Current lag per partition and total lag
- State - Active consumers or empty groups
- Members - Number of active consumer instances
- Commit frequency - How often consumers commit offsets
Identify problematic consumers
- Consistently high or growing lag
- Consumers that frequently rebalance
- Groups with zero active members but uncommitted messages
- Uneven lag distribution across partitions
Review partition distribution
Review partition distribution
Navigate to the VIP topic
Analyze partition distribution
- Partitions are evenly distributed across all brokers
- Leadership is balanced (no single broker leads most partitions)
- No brokers are excluded from the topic
- Replica assignments provide proper fault tolerance
Check for load imbalance
- Partition sizes across all partitions
- Message counts per partition
- Offset ranges (begin offset to end offset)
Track performance metrics
Track performance metrics
Navigate to the VIP topic
Review produce metrics
- Messages in per second - Produce rate over time
- Bytes in per second - Data volume throughput
- Look for unusual spikes, drops or patterns
- Establish baseline performance for capacity planning
Review consume metrics
- Messages out per second - Consume rate across all consumer groups
- Bytes out per second - Data volume being consumed
- Compare consume rate to produce rate to identify accumulation
Identify trends and anomalies
- Detect gradual throughput increases requiring capacity planning
- Identify time-of-day or day-of-week patterns
- Spot sudden changes that may indicate application issues
- Plan for peak traffic periods and scaling needs
Troubleshoot
Why does a low-volume topic appear as a VIP topic?
Why does a low-volume topic appear as a VIP topic?
Should all VIP topics have the same configuration?
Should all VIP topics have the same configuration?
What if VIP topic health score is poor?
What if VIP topic health score is poor?
- Identify issues - check all recommendations in the VIP topics section and review the risk analysis.
- Prioritize by impact - critical (data loss risk with RF < 3); high (under-replicated partitions); medium (load imbalance); low (cluster efficiency issues).
- Take action - for risk of data loss, follow the replication remediation steps. For cluster efficiency, follow partition troubleshooting steps. For load imbalance, resolve issues with partition skew.
- Verify improvement - Monitor the health score after remediation to confirm resolution