Deploy Console
Deploying Console overview
Configure Console
Conduktor Console can be configured using either a configuration fileplatform-config.yaml or environment variables. This is used to set up your organization’s environment. Configuration can be used to declare:
- Organization name
- External database (required)
- User authentication (Basic or SSO)
- Console license
We recommend using the Console UI (Settings > Clusters page) to configure Kafka cluster, schema registry and Kafka connect. This has several advantages over the YAML configuration:
- Intuitive interface with live update capabilities
- Centralized and secured with RBAC and audit logs events
- Certificate store to help with custom certificates configuration (no more JKS files and volume mounts)
Security considerations
- The configuration file should be protected by file system permissions.
- The database should have at-rest data encryption enabled on the data volume and have limited network connectivity.
Configuration file
platform-config.yaml
Bind file
Thedocker-compose below shows how to bind your platform-config.yaml file.
You can alternatively use environment variables. The CDK_IN_CONF_FILE variable is used to indicate that a configuration file is being used and the location to find it.
docker-compose.yaml
Environment override
Input configuration fields can also be provided using environment variables. Here’s an example ofdocker-compose that uses environment variables for configuration:
"docker-compose.yaml
Container user and permissions
Console is running as a non-root userconduktor-platform with UID 10001 and GID 0. All files inside the container volume /var/conduktor are owned by conduktor-platform user.
Configure memory usage
We rely on container CGroups limits and use up to 80% of the container memory limit for JVM max heap size.Configure SSL or TLS
Depending on the environment, Conduktor might need to access external services (such as Kafka clusters, SSO servers, databases or object storage) that require a custom certificate for SSL/TLS communication. You can configure this using:- Console UI (recommended) - you can manage your certificates in a dedicated screen and configure SSL authentication from the broker setup wizard.
- volume mount - this method is only required if you have LDAPS. Do not use it for Kafka or Kafka components.
| Kafka clusters | Schema registry / Kafka Connect | LDAPS, OIDC | |
|---|---|---|---|
| SSL to secure data in transit | UI | UI | UI |
| SSL to authenticate the client | UI | UI | Not supported |
Use the Conduktor certificate store
This option is recommended for Kafka, Kafka Connect and Schema Registry connections.
- .crt
- .pem
- .jks
- .p12
Upload certificates
You can add cluster configurations from Settings > Clusters page. When you add the bootstrap server to your configuration, a check will be made to validate if the certificate is issued by a valid authority. If the response indicates the certificate is not issued by a valid authority, you have two options:- Skip SSL Check: This will skip validation of the SSL certificate on your server. This is an easy option for development environments with self-signed certificates
- Upload Certificate: This option will enable you to upload the certificate (
.crt,.pem,.jksor.p12files), or paste the certificate as text
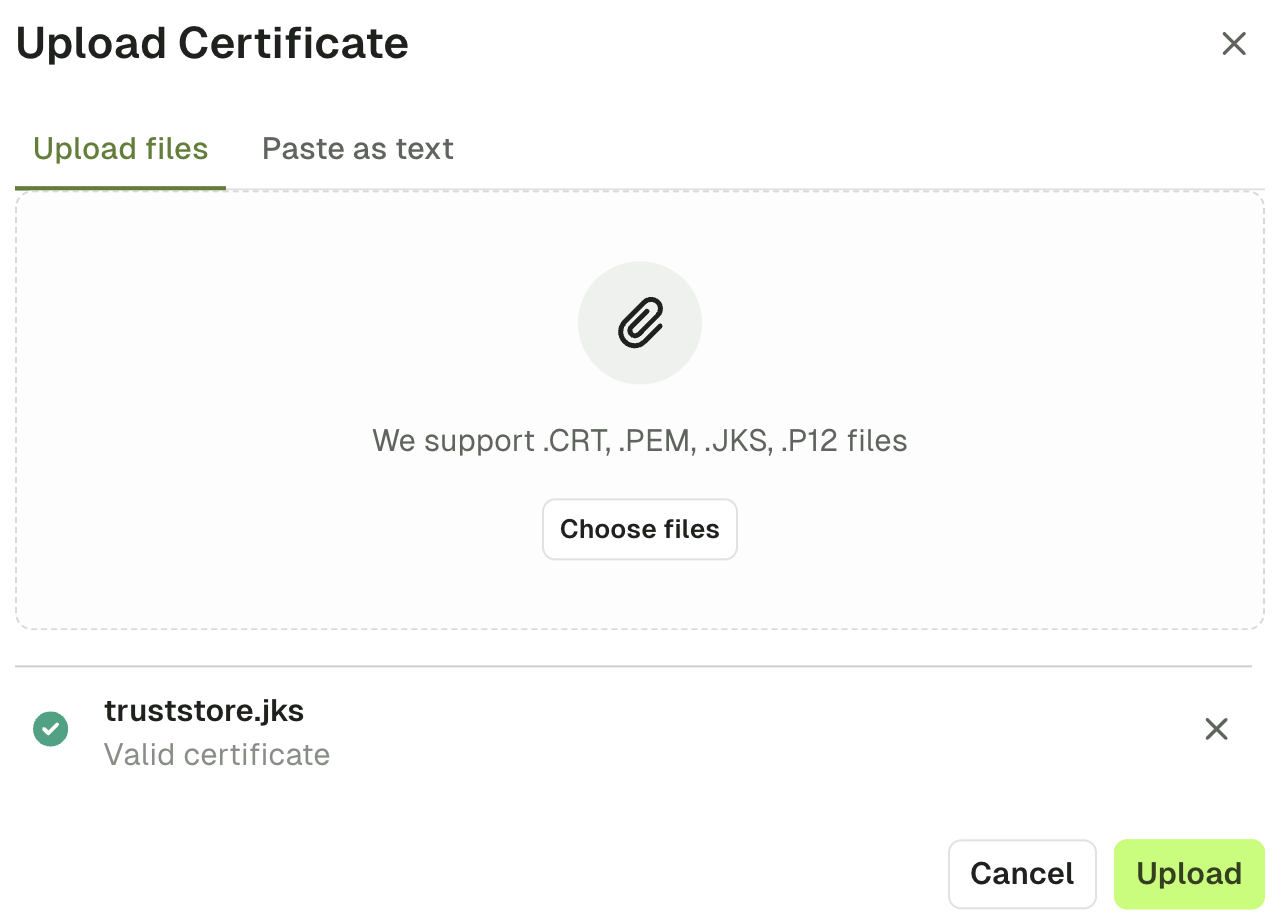 Upon uploading the certificate, you should then see the green icon indicating the connection is secure.
Upon uploading the certificate, you should then see the green icon indicating the connection is secure.

Add truststores
You can also manage organization truststores using the Settings > Certificates page. Simply add all of your certificates by uploading them or pasting them as text. In doing this, the SSL context will be derived when you configure Kafka, Kafka Connect and Schema Registry connections.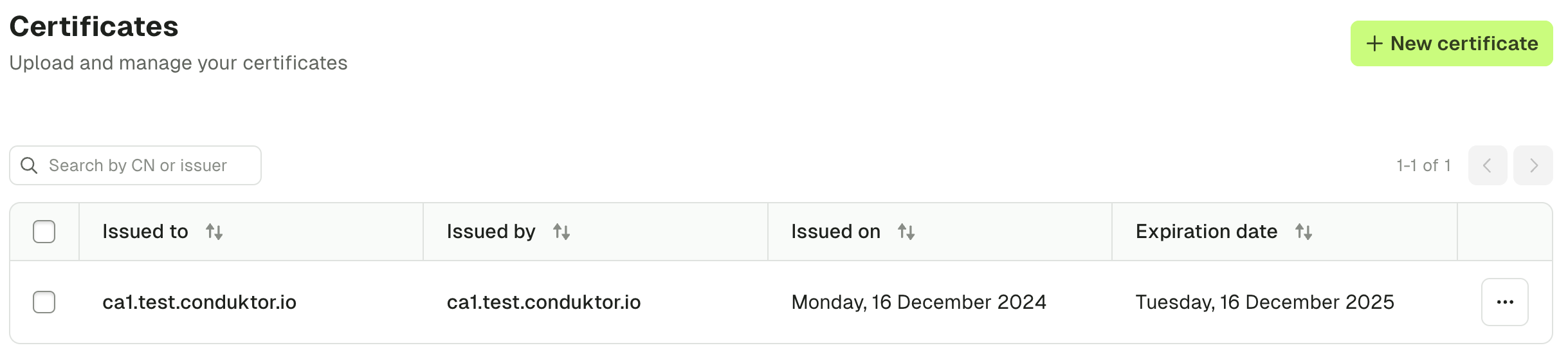
Mount custom truststore
This option is recommended for SSO, DB or other external services requiring SSL/TLS communication.
Create TrustStore (JKS) from certificate in PEM format
If you already have a truststore, you can ignore this step. You need akeytool program that is usually packaged on JDK distributions and a certificate in PEM format (.pem or .crt).
Configure custom truststore via Conduktor Console
Mount the truststore file into theconduktor-console container and pass the correct environment variables for locating truststore file inside the container (and password, if needed).
If the truststore file is truststore.jks with password changeit, mount truststore file into /opt/conduktor/certs/truststore.jks inside the container.
If run from Docker :
Client certificate authentication
This option is recommended for mTLS.
- Mutual SSL, Mutual TLS, mTLS
- Two-Way SSL, SSL Certificate Authentication
- Digital Certificate Authentication, Public Key Infrastructure (PKI) Authentication
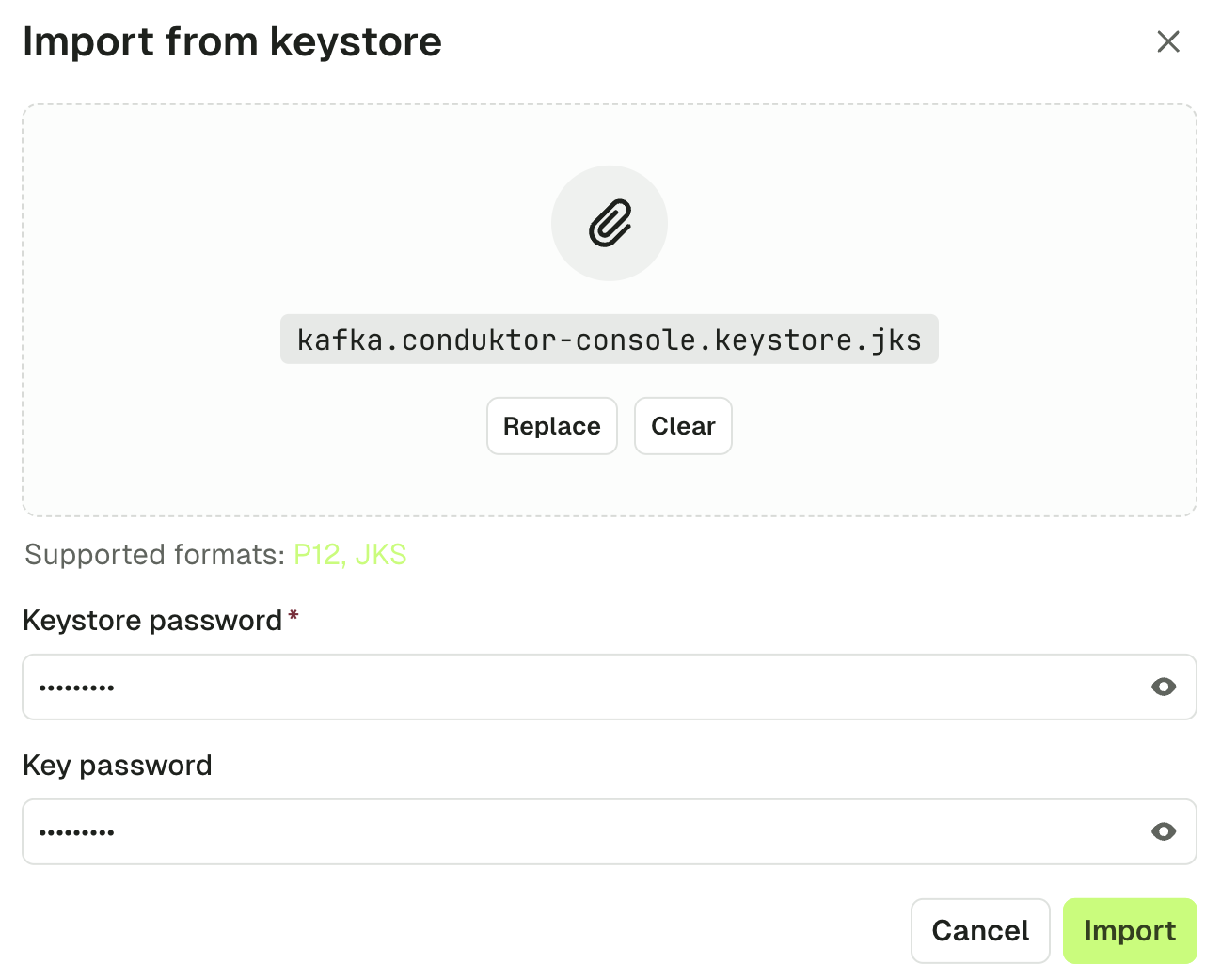
Use the UI (keystore method)
Use the keystore file from your Kafka admin or provider (in .jks or .p12 format). Click the “Import from keystore” button to select a keystore file from your filesystem.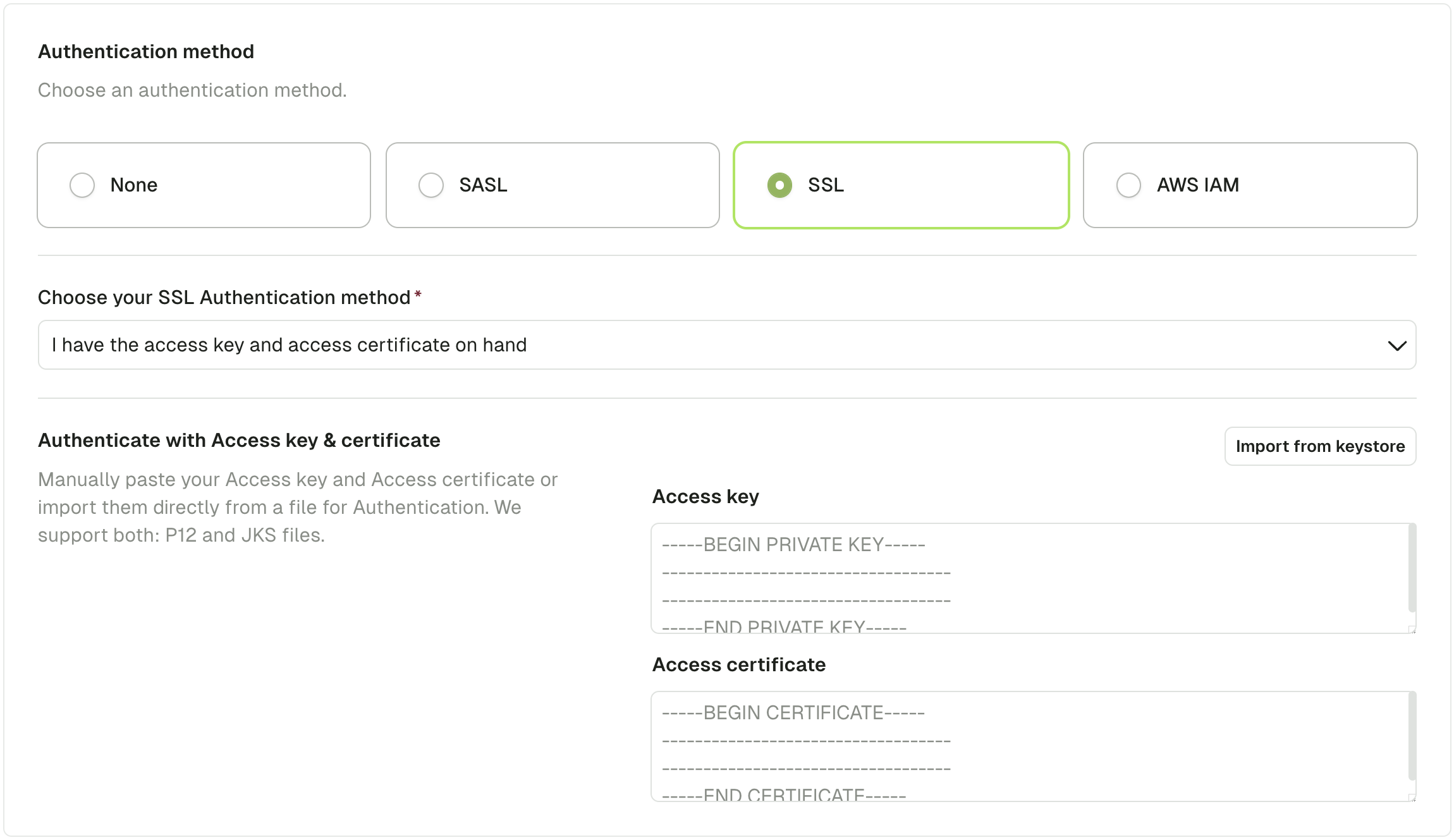 Fill in the required keystore password and key password and click “Import”.
Fill in the required keystore password and key password and click “Import”.
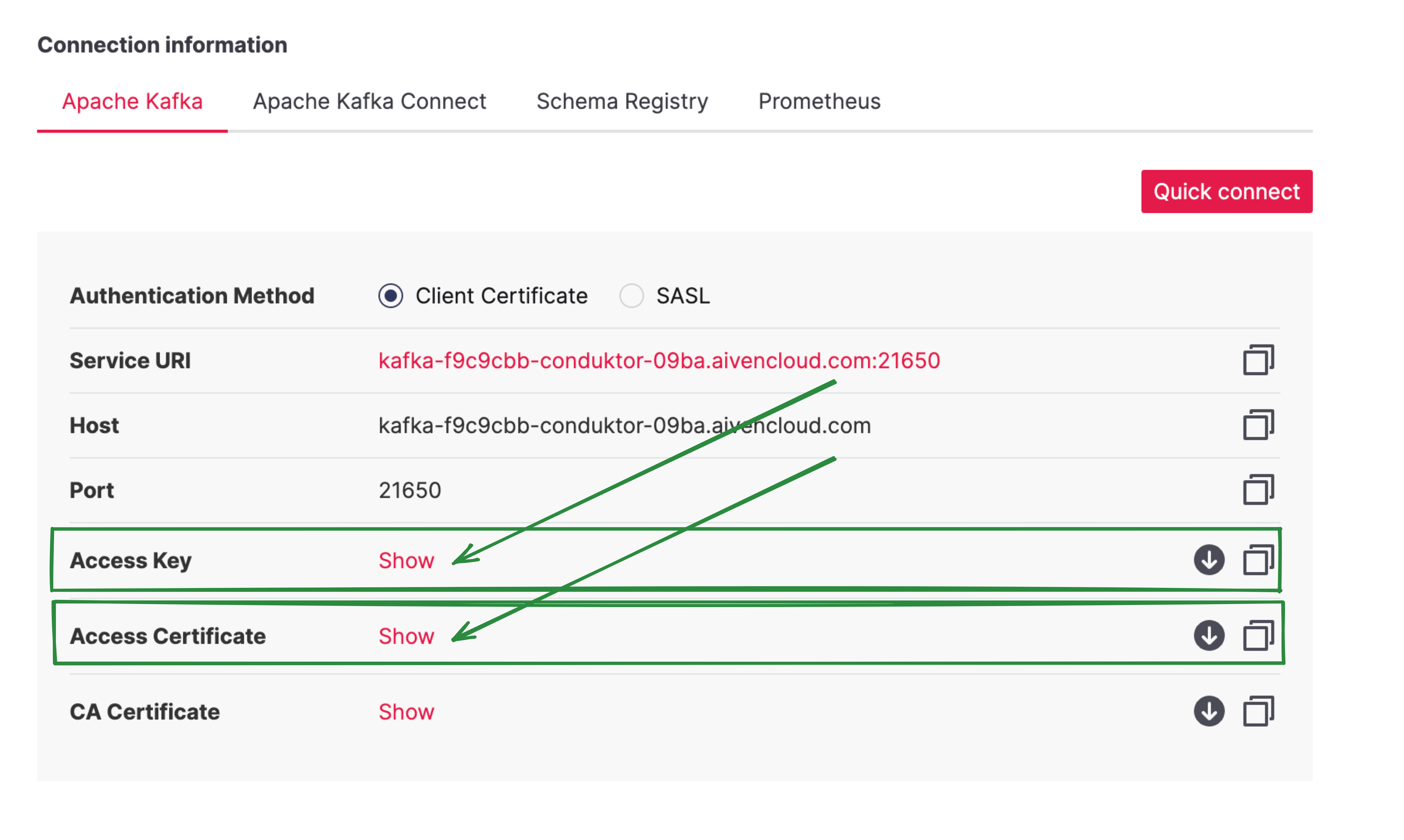
 You’ll get back to the cluster screen with the content of your keystore extracted into Access key and Access certificate.
You’ll get back to the cluster screen with the content of your keystore extracted into Access key and Access certificate.
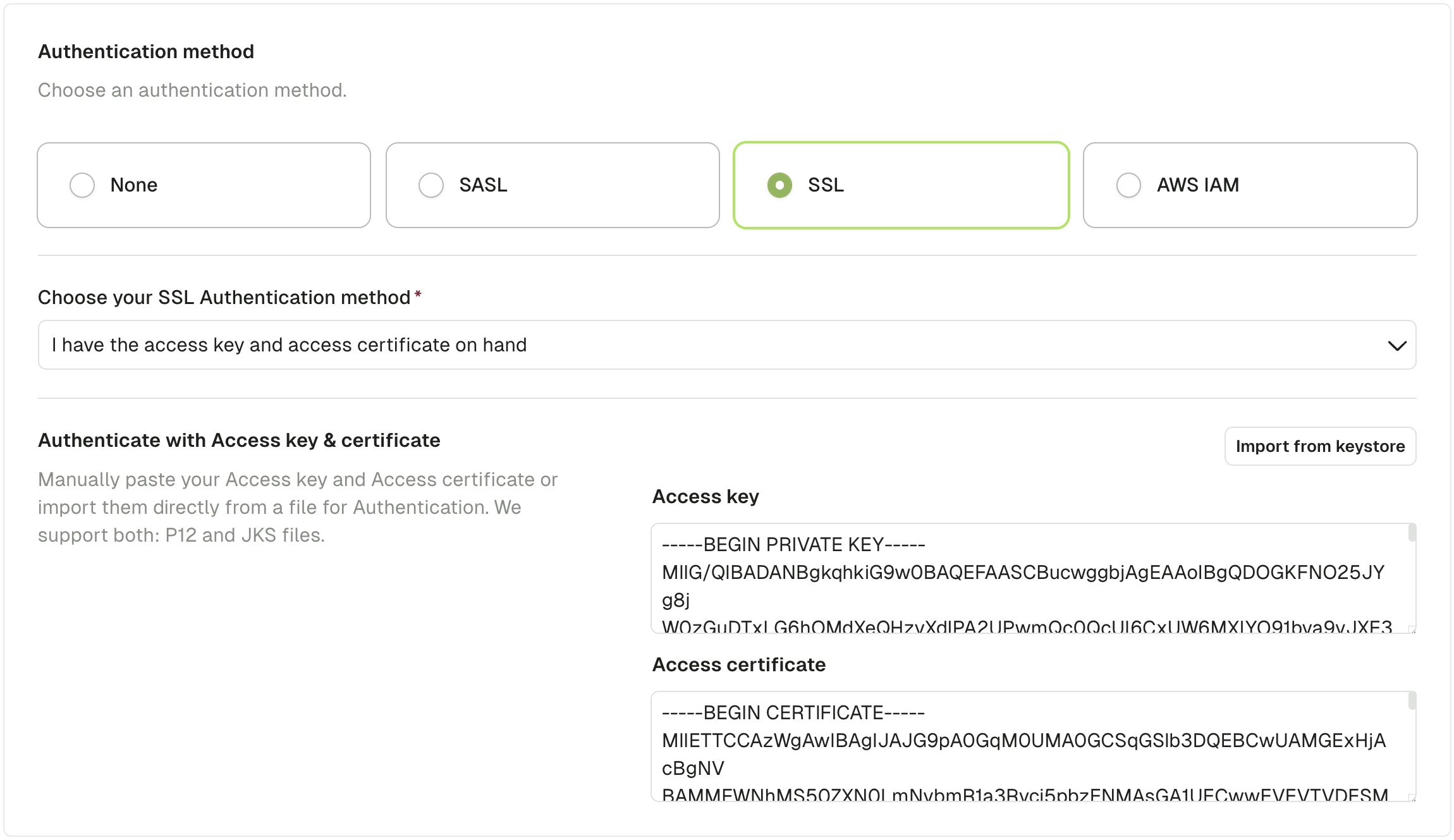
Use the UI (Access key & Access certificate method)
Your Kafka Admin or your Kafka Provider gave you 2 files for authentication.- An Access key (
.keyfile) - An Access certificate (
.pemor.crtfile)
 You can paste the contents of the two files into Conduktor or import from keystore.
You can paste the contents of the two files into Conduktor or import from keystore.
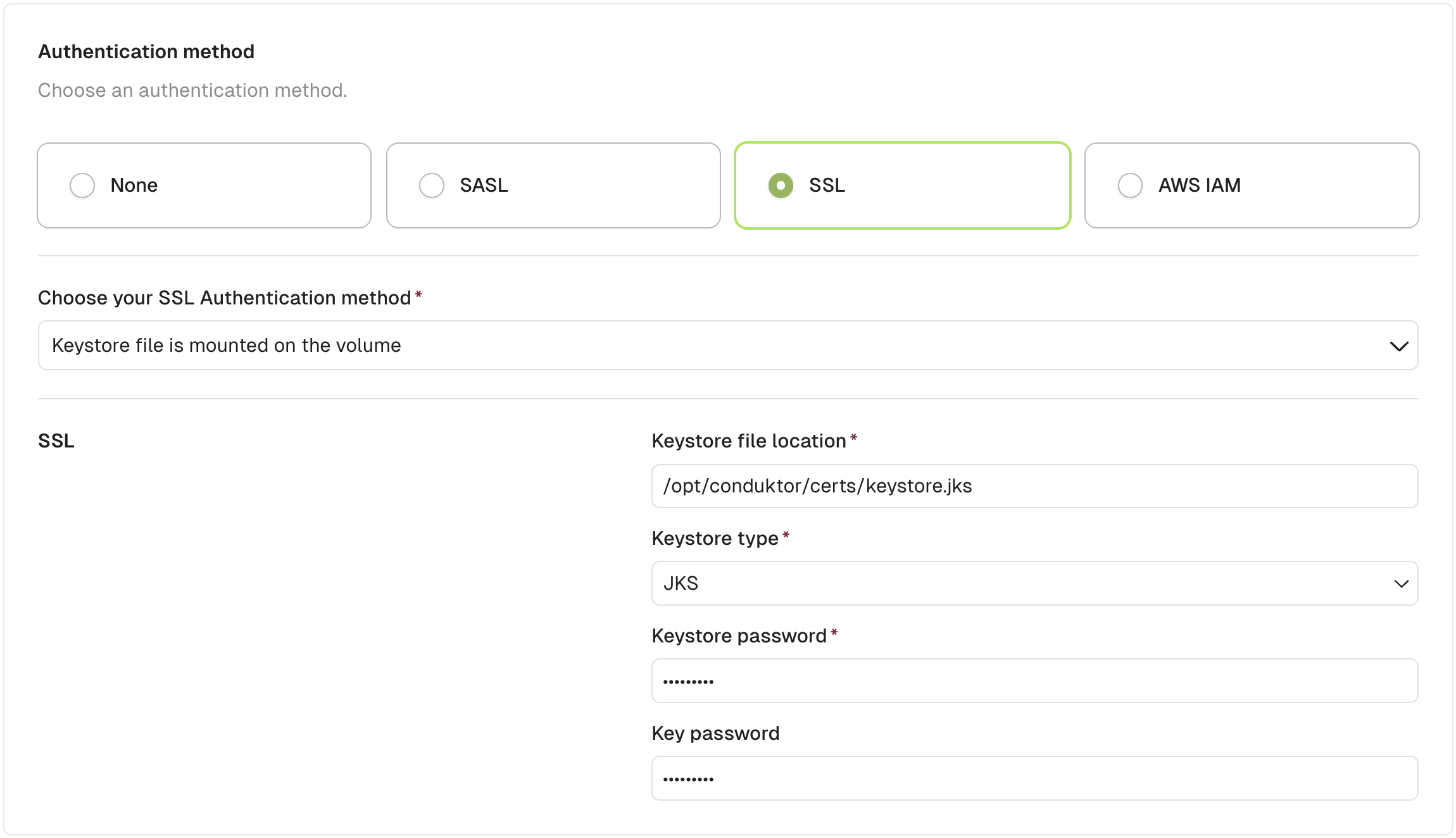
Use volume mount
You can mount the keystore file in theconduktor-console image:
Configure Postgres database
Conduktor Console requires a Postgres database to store its state.Postgres requirements
- Postgres version 13 or higher
- Provided connection role should have grant
ALL PRIVILEGESon the configured database. Console should be able to create/update/delete schemas and tables on the database. - For your Postgres deployment use at least 1-2 vCPU, 1 GB of Ram, and 10 GB of disk.
If you want to use AWS RDS or AWS Aurora as a database with Console, consider the following: Console will not work with all PostgreSQL engines within RDS, it will only work with engine versions 14.8+ / 15.3+ (other versions are not fully supported).
Database configuration properties
database: is a key/value configuration consisting of:database.url: database connection url in the format[jdbc:]postgresql://[user[:password]@][[netloc][:port],...][/dbname][?param1=value1&...]database.hosts[].host: Postgresql server hosts namedatabase.hosts[].port: Postgresql server portsdatabase.host: Postgresql server host name (Deprecated. Usedatabase.hostsinstead)database.port: Postgresql server port (Deprecated. Usedatabase.hostsinstead)database.name: Database namedatabase.username: Database login roledatabase.password: Database login passworddatabase.connection_timeout: Connection timeout option in seconds
URL format
Console supports both, the standard PostgreSQL URL and JDBC PostgreSQL. Connection username and password can be provided in the URL as basic authentication or as parameters.SSL support
By default, Console will try to connect to the database using SSL modeprefer. We plan to make this configurable in the future along with database certificate.
Setup
There are several options available when configuring an external database:-
From a single connection URL
- With the
CDK_DATABASE_URLenvironment variable. - With the
database.urlconfiguration field. In either case, this connection url is using a standard PostgreSQL url in the format[jdbc:]postgresql://[user[:password]@][[netloc][:port],...][/dbname][?param1=value1&...]
- With the
-
From decomposed configuration fields
- With the
CDK_DATABASE_*env vars. - With the
database.*on configuration file.
- With the
Example
- If all connection URLs and decomposed configuration fields are provided, the decomposed configuration fields take priority.
- If an invalid connection URL or a mandatory configuration field (
host,usernameorname) is missing, Conduktor will fail gracefully with a meaningful error message. - Before Console v1.2.0, the
EMBEDDED_POSTGRES=falsewas mandatory to enable external Postgresql configuration.
Multi-host configuration
If you have a multi-host setup, you can configure the database connection with a list of hosts. Conduktor uses a PostgreSQL JDBC driver to connect to the database that supports multiple hosts in the connection url. To configure a multi-host setup, you can use thedatabase.url configuration field with a list of hosts separated by commas:
targetServerType to specify the target server type for the connection:
targetServerType are supported: any, primary, master, slave, secondary, preferSlave, preferSecondary and preferPrimary.
Debug Console
Conduktor Console Docker image runs on Ubuntu Linux. It runs multiple services in a single Docker container. These services are supervised by supervisord. To troubleshoot Console:- Verify that Console is up and running.
- Check the logs and send them to our support team if necessary.
1. Verify that Conduktor is up and running
First, verify that all the components are running.If you’re using an external Kafka installation and external database, you will only need to verify that the You can save these logs in a file:
Get containers status
Output
conduktor-console container is showing healthy as the STATUS.If Console is showing an “exited” status, check the Docker logs by running the command (with the appropriate container name):Get container logs
Store logs in a file
2. Get the logs and send them to support
Logs are kept in/var/conduktor/log. You can see them using:
List log files
Output
Configuration properties and environment variables
Docker image environment variables
| Environment variable | Description | Default Value | Since Version |
|---|---|---|---|
| Logs | |||
CDK_DEBUG | Enable Console debug logs (equivalent to CDK_ROOT_LOG_LEVEL=DEBUG) | false | 1.0.0 |
CDK_ROOT_LOG_LEVEL | Set the Console global log level (one of DEBUG, INFO, WARN, ERROR) | INFO | 1.11.0 |
CDK_ROOT_LOG_FORMAT | Set logs format (one of TEXT, JSON) | TEXT | 1.26.0 |
CDK_ROOT_LOG_COLOR | Enable ANSI colors in logs | true | 1.11.0 |
CDK_LOG_TIMEZONE | Timezone for dates in logs (in Olson timezone ID format, e.g. Europe/Paris) | TZ environment variable or UTC if TZ is not defined | 1.28.0 |
| Proxy settings | |||
CDK_HTTP_PROXY_HOST | Proxy hostname | ∅ | 1.10.0 |
CDK_HTTP_PROXY_PORT | Proxy port | 80 | 1.10.0 |
CDK_HTTP_NON_PROXY_HOSTS | List of hosts that should be reached directly, bypassing the proxy. Hosts must be separated by |, end with a * for wildcards, and not contain any /. | ∅ | 1.10.0 |
CDK_HTTP_PROXY_USERNAME | Proxy username | ∅ | 1.10.0 |
CDK_HTTP_PROXY_PASSWORD | Proxy password | ∅ | 1.10.0 |
| SSL | |||
CDK_SSL_TRUSTSTORE_PATH | Truststore file path used by Console for Kafka, SSO, S3,… clients SSL/TLS verification | ∅ | 1.5.0 |
CDK_SSL_TRUSTSTORE_PASSWORD | Truststore password (optional) | ∅ | 1.5.0 |
CDK_SSL_TRUSTSTORE_TYPE | Truststore type (optional) | jks | 1.5.0 |
CDK_SSL_DEBUG | Enable SSL/TLS debug logs | false | 1.9.0 |
| Java | |||
CDK_GLOBAL_JAVA_OPTS | Custom JAVA_OPTS parameters passed to Console | ∅ | 1.10.0 |
CONSOLE_MEMORY_OPTS | Configure Java memory options | -XX:+UseContainerSupport -XX:MaxRAMPercentage=80 | 1.18.0 |
| Console | |||
CDK_LISTENING_PORT | Console listening port | 8080 | 1.2.0 |
CDK_VOLUME_DIR | Volume directory where Console stores data | /var/conduktor | 1.0.2 |
CDK_IN_CONF_FILE | Console configuration file location | /opt/conduktor/default-platform-config.yaml | 1.0.2 |
CDK_PLUGINS_DIR | Volume directory for custom deserializer plugins | /opt/conduktor/plugins | 1.22.0 |
| Nginx | |||
PROXY_BUFFER_SIZE | Tune internal Nginx proxy_buffer_size | 8k | 1.16.0 |
Console properties reference
You have multiple options to configure Console: via environment variables, or via a YAML configuration file. You can find a mapping of the configuration fields in theplatform-config.yaml to environment variables below.
Environment variables can be set on the container or imported from a file. When importing from a file, mount the file into the container and provide its path by setting the environment variable CDK_ENV_FILE. Use a .env file with key value pairs.
Sourcing environment variables from $CDK_ENV_FILE, or warn if set and the file is not found
Lists start at index 0 and are provided using
_idx_ syntax.YAML property cases
YAML configuration supports multiple case formats (camelCase/kebab-case/lowercase) for property fragments such as:
clusters[].schemaRegistry.ignoreUntrustedCertificateclusters[].schema-registry.ignore-untrusted-certificateclusters[].schemaregistry.ignoreuntrustedcertificate
Environment variable conversion
At startup, Conduktor Console will merge environment variables and YAML based configuration files into one unified configuration. The conversion rules are:- Filter for environment variables that start with
CDK_ - Remove the
CDK_prefix - Convert the variable name to lowercase
- Replace
_with.for nested properties - Replace
_[0-9]+_with[0-9].for list properties. (Lists start at index 0)
CDK_DATABASE_URL will be converted to database.url, or CDK_SSO_OAUTH2_0_OPENID_ISSUER will be converted into sso.oauth2[0].openid.issuer.
The YAML equivalent would be:
UPPER-KEBAB-CASE will be converted to kebab-case in the YAML configuration.
Conversion edge cases
Because of YAML multiple case formats support, the conversion rules have some edge cases when trying to mix environment variables and YAML configuration. Extra rules when mixing environment variables and YAML configuration:- Don’t use
camelCasein YAML configuration. Usekebab-caseorlowercase - Stick to one compatible case format for a given property fragment using the following compatibility matrix
| YAML\Environment | UPPER-KEBAB-CASE | UPPERCASE |
|---|---|---|
kebab-case | ✅ | 🚫 |
lowercase | 🚫 | ✅ |
camelCase | 🚫 | 🚫 |
CDK_CLUSTERS_0_SCHEMAREGISTRY_IGNOREUNTRUSTEDCERTIFICATE environment variable:
CDK_CLUSTERS_0_SCHEMA-REGISTRY_IGNORE-UNTRUSTED-CERTIFICATE, that’s why camelCase is not recommended in YAML configuration when mixing with environment variables.
Support of shell expansion in the YAML configuration file
Console supports shell expansion for environment variables and home tilde~. This is useful if you have to use custom environment variables in your configuration.
For example, you can use the following syntax:
YAML configuration file
| Environment variable | Value |
|---|---|
DB_LOGIN | usr |
DB_PWD | pwd |
DB_HOST | some_host |
DB_NAME | cdk |
Expanded configuration
$$. For example, if you want admin.password to be secret$123, you should set admin.password: "secret$$123".
File path environment variables
When an environment variable ending with_FILE is set to a file path, its corresponding unprefixed environment variable will be replaced with the content of that file.
For example, if you set CDK_LICENSE_FILE=/run/secrets/license, the value of CDK_LICENSE will be overridden by the content of the file located at /run/secrets/license.
The
CDK_IN_CONF_FILE is not supported.Global properties
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
organization.name | Your organization’s name | CDK_ORGANIZATION_NAME | false | string | "default" |
admin.email | Your organization’s root administrator account email | CDK_ADMIN_EMAIL | true | string | ∅ |
admin.password | Your organization’s root administrator account password. Must be at least 8 characters in length, and include at least 1 uppercase letter, 1 lowercase letter, 1 number, and 1 special symbol | CDK_ADMIN_PASSWORD | true | string | ∅ |
license | Enterprise license key. If not provided, fallback to free plan. | CDK_LICENSE or LICENSE_KEY | false | string | ∅ |
platform.external.url | Force Console external URL. Useful for SSO callback URL when using a reverse proxy. By default, Console will try to guess it automatically using X-Forwarded-* headers coming from upstream reverse proxy. | CDK_PLATFORM_EXTERNAL_URL | false | string | ∅ |
platform.https.cert.path | Path to the SSL certificate file | CDK_PLATFORM_HTTPS_CERT_PATH | false | string | ∅ |
platform.https.key.path | Path to the SSL private key file | CDK_PLATFORM_HTTPS_KEY_PATH | false | string | ∅ |
enable_product_metrics | In order to improve Conduktor Console, we collect anonymous usage metrics. Set to false, this configuration disable all of our metrics collection. | CDK_ENABLE_PRODUCT_METRICS | false | boolean | true |
Database properties
See database configuration for details.| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
database.url | External PostgreSQL configuration URL in format [jdbc:]postgresql://[user[:password]@][[netloc][:port],...][/dbname][?param1=value1&...] | CDK_DATABASE_URL | false | string | ∅ |
database.hosts[].host | External PostgreSQL servers hostname | CDK_DATABASE_HOSTS_0_HOST | false | string | ∅ |
database.hosts[].port | External PostgreSQL servers port | CDK_DATABASE_HOSTS_0_PORT | false | int | ∅ |
database.host | External PostgreSQL server hostname (Deprecated, use database.hosts instead) | CDK_DATABASE_HOST | false | string | ∅ |
database.port | External PostgreSQL server port (Deprecated, use database.hosts instead) | CDK_DATABASE_PORT | false | int | ∅ |
database.name | External PostgreSQL database name | CDK_DATABASE_NAME | false | string | ∅ |
database.username | External PostgreSQL login role | CDK_DATABASE_USERNAME | false | string | ∅ |
database.password | External PostgreSQL login password | CDK_DATABASE_PASSWORD | false | string | ∅ |
database.connection_timeout | External PostgreSQL connection timeout in seconds | CDK_DATABASE_CONNECTIONTIMEOUT | false | int | ∅ |
Session lifetime properties
| Property | Description | Environment variable | Mandatory | Type | Default value |
|---|---|---|---|---|---|
auth.sessionLifetime | Max session lifetime in seconds | CDK_AUTH_SESSIONLIFETIME | false | int | 259200 |
auth.idleTimeout | Max idle session time in seconds (access token lifetime). Should be lower than auth.sessionLifetime | CDK_AUTH_IDLETIMEOUT | false | int | 259200 |
Local users properties
Optional local account list used to log into Console.| Property | Description | Environment variable | Mandatory | Type | Default value |
|---|---|---|---|---|---|
auth.local-users[].email | User login | CDK_AUTH_LOCALUSERS_0_EMAIL | true | string | "admin@conduktor.io" |
auth.local-users[].password | User password | CDK_AUTH_LOCALUSERS_0_PASSWORD | true | string | "admin" |
Monitoring properties
To see monitoring graphs and use alerts, you have to ensure that Cortex is also deployed.Monitoring Configuration for Console
First, we need to configure Console to connect to Cortex services. By default, Cortex ports are:- Query port: 9009
- Alert manager port: 9010
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
monitoring.cortex-url | Cortex Search Query URL with port 9009 | CDK_MONITORING_CORTEXURL | true | string | ∅ |
monitoring.alert-manager-url | Cortex Alert Manager URL with port 9010 | CDK_MONITORING_ALERTMANAGERURL | true | string | ∅ |
monitoring.callback-url | Console API | CDK_MONITORING_CALLBACKURL | true | string | ∅ |
monitoring.notifications-callback-url | Where the Slack notification should redirect | CDK_MONITORING_NOTIFICATIONCALLBACKURL | true | string | ∅ |
monitoring.clusters-refresh-interval | Refresh rate in seconds for metrics | CDK_MONITORING_CLUSTERREFRESHINTERVAL | false | int | 60 |
monitoring.use-aggregated-metrics | Defines whether use the new aggregated metrics in the Console graphs | CDK_MONITORING_USEAGGREGATEDMETRICS | No | Boolean | false |
monitoring.enable-non-aggregated-metrics | Toggles the collection of obsolete granular metrics | CDK_MONITORING_ENABLENONAGGREGATEDMETRICS | No | Boolean | true |
monitoring.use-aggregated-metrics and monitoring.enable-non-aggregated-metrics are temporary flags to help you transition to the new metrics collection system. They will be removed in a future release.Swap their default value if you experience performance issues when Console is connected with large Kafka clusters:Monitoring configuration for Cortex
See Cortex configuration for details.SSO properties
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
sso.ignoreUntrustedCertificate | Disable SSL checks | CDK_SSO_IGNOREUNTRUSTEDCERTIFICATE | false | boolean | false |
sso.trustedCertificates | SSL public certificates for SSO authentication (LDAPS and OAuth2) as PEM | CDK_SSO_TRUSTEDCERTIFICATES | false | string | ∅ |
LDAP properties
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
sso.ldap[].name | Ldap connection name | CDK_SSO_LDAP_0_NAME | true | string | ∅ |
sso.ldap[].server | Ldap server host and port | CDK_SSO_LDAP_0_SERVER | true | string | ∅ |
sso.ldap[].managerDn | Sets the manager DN | CDK_SSO_LDAP_0_MANAGERDN | true | string | ∅ |
sso.ldap[].managerPassword | Sets the manager password | CDK_SSO_LDAP_0_MANAGERPASSWORD | true | string | ∅ |
sso.ldap[].search-subtree | Sets if the subtree should be searched. | CDK_SSO_LDAP_0_SEARCHSUBTREE | false | boolean | true |
sso.ldap[].search-base | Sets the base DN to search. | CDK_SSO_LDAP_0_SEARCHBASE | true | string | ∅ |
sso.ldap[].search-filter | Sets the search filter. By default, the filter is set to (uid={0}) for users using class type InetOrgPerson. | CDK_SSO_LDAP_0_SEARCHFILTER | false | string | "(uid={0})" |
sso.ldap[].search-attributes | Sets the attributes list to return. By default, all attributes are returned. Platform search for uid, cn, mail, email, givenName, sn, displayName attributes to map into user token. | CDK_SSO_LDAP_0_SEARCHATTRIBUTES | false | string array | [] |
sso.ldap[].groups-enabled | Sets if group search is enabled. | CDK_SSO_LDAP_0_GROUPSENABLED | false | boolean | false |
sso.ldap[].groups-subtree | Sets if the subtree should be searched. | CDK_SSO_LDAP_0_GROUPSSUBTREE | false | boolean | true |
sso.ldap[].groups-base | Sets the base DN to search from. | CDK_SSO_LDAP_0_GROUPSBASE | true | string | ∅ |
sso.ldap[].groups-filter | Sets the group search filter. If using group class type GroupOfUniqueNames use the filter "uniqueMember={0}". For group class GroupOfNames use "member={0}". | CDK_SSO_LDAP_0_GROUPSFILTER | false | string | "uniquemember={0}" |
sso.ldap[].groups-filter-attribute | Sets the name of the user attribute to bind to the group search filter. Defaults to the user’s DN. | CDK_SSO_LDAP_0_GROUPSFILTERATTRIBUTE | false | string | ∅ |
sso.ldap[].groups-attribute | Sets the group attribute name. Defaults to cn. | CDK_SSO_LDAP_0_GROUPSATTRIBUTE | false | string | "cn" |
sso.ldap[].properties | Additional properties that will be passed to identity provider context. | CDK_SSO_LDAP_0_PROPERTIES | false | dictionary | ∅ |
OAuth2 properties
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
sso.oauth2[].name | OAuth2 connection name | CDK_SSO_OAUTH2_0_NAME | true | string | ∅ |
sso.oauth2[].default | Use as default | CDK_SSO_OAUTH2_0_DEFAULT | true | boolean | ∅ |
sso.oauth2[].client-id | OAuth2 client ID | CDK_SSO_OAUTH2_0_CLIENTID | true | string | ∅ |
sso.oauth2[].client-secret | OAuth2 client secret | CDK_SSO_OAUTH2_0_CLIENTSECRET | true | string | ∅ |
sso.oauth2[].openid.issuer | Issuer to check on token | CDK_SSO_OAUTH2_0_OPENID_ISSUER | true | string | ∅ |
sso.oauth2[].scopes | Scopes to be requested in the client credentials request | CDK_SSO_OAUTH2_0_SCOPES | true | string | [] |
sso.oauth2[].groups-claim | Group attribute from your identity provider | CDK_SSO_OAUTH2_0_GROUPSCLAIM | false | string | ∅ |
sso.oauth2[].username-claim | Email attribute from your identity provider | CDK_SSO_OAUTH2_0_USERNAMECLAIM | false | string | email |
sso.oauth2[].allow-unsigned-id-tokens | Allow unsigned ID tokens | CDK_SSO_OAUTH2_0_ALLOWUNSIGNEDIDTOKENS | false | boolean | false |
sso.oauth2[].preferred-jws-algorithm | Configure preferred JWS algorithm | CDK_SSO_OAUTH2_0_PREFERREDJWSALGORITHM | false | string one of: “HS256”, “HS384”, “HS512”, “RS256”, “RS384”, “RS512”, “ES256”, “ES256K”, “ES384”, “ES512”, “PS256”, “PS384”, “PS512”, “EdDSA” | ∅ |
sso.oauth2-logout | Wether the central identity provider logout should be called or not | CDK_SSO_OAUTH2LOGOUT | false | boolean | true |
JWT auth properties
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
sso.jwt-auth.issuer | Issuer of your identity provider | CDK_SSO_JWTAUTH_ISSUER | true | string | ∅ |
sso.jwt-auth.username-claim | Email attribute from your identity provider | CDK_SSO_JWTAUTH_USERNAMECLAIM | false | string | email |
sso.jwt-auth.groups-claim | Group attribute from your identity provider | CDK_SSO_JWTAUTH_GROUPSCLAIM | false | string | groups |
sso.jwt-auth.api-key-claim | API key attribute from your identity provider | CDK_SSO_JWTAUTH_APIKEYCLAIM | false | string | apikey |
Kafka cluster properties
The new recommended way to configure clusters is through the CLI and YAML manifests.
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
clusters[].id | String used to uniquely identify your Kafka cluster | CDK_CLUSTERS_0_ID | true | string | ∅ |
clusters[].name | Alias or user-friendly name for your Kafka cluster | CDK_CLUSTERS_0_NAME | true | string | ∅ |
clusters[].color | Attach a color to associate with your cluster in the UI | CDK_CLUSTERS_0_COLOR | false | string in hexadecimal format (#FFFFFF) | random |
clusters[].ignoreUntrustedCertificate | Skip SSL certificate validation | CDK_CLUSTERS_0_IGNOREUNTRUSTEDCERTIFICATE | false | boolean | false |
clusters[].bootstrapServers | List of host:port for your Kafka brokers separated by coma , | CDK_CLUSTERS_0_BOOTSTRAPSERVERS | true | string | ∅ |
clusters[].properties | Any cluster configuration properties | CDK_CLUSTERS_0_PROPERTIES | false | string where each line is a property | ∅ |
Kafka vendor specific properties
Note that you only need to set the Kafka cluster properties to use the core features of Console. However, you can get additional benefits by setting the flavor of your cluster. This corresponds to theProvider tab of your cluster configuration in Console.
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
clusters[].kafkaFlavor.type | Kafka flavor type, one of Confluent, Aiven, Gateway | CDK_CLUSTERS_0_KAFKAFLAVOR_TYPE | false | string | ∅ |
Flavor is Confluent | Manage Confluent Cloud service accounts, API keys, and ACLs | ||||
clusters[].kafkaFlavor.key | Confluent Cloud API Key | CDK_CLUSTERS_0_KAFKAFLAVOR_KEY | true | string | ∅ |
clusters[].kafkaFlavor.secret | Confluent Cloud API Secret | CDK_CLUSTERS_0_KAFKAFLAVOR_SECRET | true | string | ∅ |
clusters[].kafkaFlavor.confluentEnvironmentId | Confluent Environment ID | CDK_CLUSTERS_0_KAFKAFLAVOR_CONFLUENTENVIRONMENTID | true | string | ∅ |
clusters[].kafkaFlavor.confluentClusterId | Confluent Cluster ID | CDK_CLUSTERS_0_KAFKAFLAVOR_CONFLUENTCLUSTERID | true | string | ∅ |
Flavor is Aiven | Manage Aiven service accounts and ACLs | ||||
clusters[].kafkaFlavor.apiToken | Aiven API token | CDK_CLUSTERS_0_KAFKAFLAVOR_APITOKEN | true | string | ∅ |
clusters[].kafkaFlavor.project | Aiven project | CDK_CLUSTERS_0_KAFKAFLAVOR_PROJECT | true | string | ∅ |
clusters[].kafkaFlavor.serviceName | Aiven service name | CDK_CLUSTERS_0_KAFKAFLAVOR_SERVICENAME | true | string | ∅ |
Flavor is Gateway | Manage Conduktor Gateway interceptors | ||||
clusters[].kafkaFlavor.url | Gateway API endpoint URL | CDK_CLUSTERS_0_KAFKAFLAVOR_URL | true | string | ∅ |
clusters[].kafkaFlavor.user | Gateway API username | CDK_CLUSTERS_0_KAFKAFLAVOR_USER | true | string | ∅ |
clusters[].kafkaFlavor.password | Gateway API password | CDK_CLUSTERS_0_KAFKAFLAVOR_PASSWORD | true | string | ∅ |
clusters[].kafkaFlavor.virtualCluster | Gateway virtual cluster | CDK_CLUSTERS_0_KAFKAFLAVOR_VIRTUALCLUSTER | true | string | ∅ |
Schema registry properties
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
clusters[].schemaRegistry.url | The schema registry URL | CDK_CLUSTERS_0_SCHEMAREGISTRY_URL | true | string | ∅ |
clusters[].schemaRegistry.ignoreUntrustedCertificate | Skip SSL certificate validation | CDK_CLUSTERS_0_SCHEMAREGISTRY_IGNOREUNTRUSTEDCERTIFICATE | false | boolean | false |
clusters[].schemaRegistry.properties | Any schema registry configuration parameters | CDK_CLUSTERS_0_SCHEMAREGISTRY_PROPERTIES | false | string where each line is a property | ∅ |
| Basic Authentication | |||||
clusters[].schemaRegistry.security.username | Basic auth username | CDK_CLUSTERS_0_SCHEMAREGISTRY_SECURITY_USERNAME | false | string | ∅ |
clusters[].schemaRegistry.security.password | Basic auth password | CDK_CLUSTERS_0_SCHEMAREGISTRY_SECURITY_PASSWORD | false | string | ∅ |
| Bearer Token Authentication | |||||
clusters[].schemaRegistry.security.token | Bearer auth token | CDK_CLUSTERS_0_SCHEMAREGISTRY_SECURITY_TOKEN | false | string | ∅ |
| mTLS Authentication | |||||
clusters[].schemaRegistry.security.key | Access Key | CDK_CLUSTERS_0_SCHEMAREGISTRY_SECURITY_KEY | false | string | ∅ |
clusters[].schemaRegistry.security.certificateChain | Access certificate | CDK_CLUSTERS_0_SCHEMAREGISTRY_SECURITY_CERTIFICATECHAIN | false | string | ∅ |
Amazon Glue schema registry properties
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
clusters[].schemaRegistry.region | The Glue schema registry region | CDK_CLUSTERS_0_SCHEMAREGISTRY_REGION | true | string | ∅ |
clusters[].schemaRegistry.registryName | The Glue schema registry name | CDK_CLUSTERS_0_SCHEMAREGISTRY_REGISTRYNAME | false | string | ∅ |
clusters[].schemaRegistry.amazonSecurity.type | Authentication with credentials, one of Credentials, FromContext, FromRole | CDK_CLUSTERS_0_SCHEMAREGISTRY_AMAZONSECURITY_TYPE | true | string | ∅ |
| Credentials Security | |||||
clusters[].schemaRegistry.amazonSecurity.accessKeyId | Credentials auth access key | CDK_CLUSTERS_0_SCHEMAREGISTRY_AMAZONSECURITY_ACCESSKEYID | true | string | ∅ |
clusters[].schemaRegistry.amazonSecurity.secretKey | Credentials auth secret key | CDK_CLUSTERS_0_SCHEMAREGISTRY_AMAZONSECURITY_SECRETKEY | true | string | ∅ |
| FromContext Security | |||||
clusters[].schemaRegistry.amazonSecurity.profile | Authentication profile | CDK_CLUSTERS_0_SCHEMAREGISTRY_AMAZONSECURITY_PROFILE | false | string | ∅ |
| FromRole Security | |||||
clusters[].schemaRegistry.amazonSecurity.role | Authentication role | CDK_CLUSTERS_0_SCHEMAREGISTRY_AMAZONSECURITY_ROLE | true | string | ∅ |
Kafka Connect properties
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
clusters[].kafkaConnects[].id | String used to uniquely identify your Kafka Connect | CDK_CLUSTERS_0_KAFKACONNECTS_0_ID | true | string | ∅ |
clusters[].kafkaConnects[].name | Name your Kafka Connect | CDK_CLUSTERS_0_KAFKACONNECTS_0_NAME | true | string | ∅ |
clusters[].kafkaConnects[].url | The Kafka connect URL | CDK_CLUSTERS_0_KAFKACONNECTS_0_URL | true | string | ∅ |
clusters[].kafkaConnects[].headers | Optional additional headers (ie: X-API-Token=123,X-From=Test) | CDK_CLUSTERS_0_KAFKACONNECTS_0_HEADERS | false | string | ∅ |
clusters[].kafkaConnects[].ignoreUntrustedCertificate | Skip SSL certificate validation | CDK_CLUSTERS_0_KAFKACONNECTS_0_IGNOREUNTRUSTEDCERTIFICATE | false | boolean | false |
| Basic Authentication | |||||
clusters[].kafkaConnects[].security.username | Basic auth username | CDK_CLUSTERS_0_KAFKACONNECTS_0_SECURITY_USERNAME | false | string | ∅ |
clusters[].kafkaConnects[].security.password | Basic auth password | CDK_CLUSTERS_0_KAFKACONNECTS_0_SECURITY_PASSWORD | false | string | ∅ |
| Bearer Token Authentication | |||||
clusters[].kafkaConnects[].security.token | Bearer token | CDK_CLUSTERS_0_KAFKACONNECTS_0_SECURITY_TOKEN | false | string | ∅ |
| mTLS Authentication | |||||
clusters[].kafkaConnects[].security.key | Access key | CDK_CLUSTERS_0_KAFKACONNECTS_0_SECURITY_KEY | false | string | ∅ |
clusters[].kafkaConnects[].security.certificateChain | Access certificate | CDK_CLUSTERS_0_KAFKACONNECTS_0_SECURITY_CERTIFICATECHAIN | false | string | ∅ |
ksqlDB properties
We support ksqlDB integration as of Conduktor Console v1.21.0.| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
clusters[].ksqlDBs[].id | String used to uniquely identify your ksqlDB Cluster | CDK_CLUSTERS_0_KSQLDBS_0_ID | true | string | ∅ |
clusters[].ksqlDBs[].name | Name of your ksqlDB Cluster | CDK_CLUSTERS_0_KSQLDBS_0_NAME | true | string | ∅ |
clusters[].ksqlDBs[].url | The ksqlDB API URL | CDK_CLUSTERS_0_KSQLDBS_0_URL | true | string | ∅ |
clusters[].ksqlDBs[].ignoreUntrustedCertificate | Skip SSL certificate validation | CDK_CLUSTERS_0_KSQLDBS_0_IGNOREUNTRUSTEDCERTIFICATE | false | boolean | false |
| Basic Authentication | |||||
clusters[].ksqlDBs[].security.username | Basic auth username | CDK_CLUSTERS_0_KSQLDBS_0_SECURITY_USERNAME | false | string | ∅ |
clusters[].ksqlDBs[].security.password | Basic auth password | CDK_CLUSTERS_0_KSQLDBS_0_SECURITY_PASSWORD | false | string | ∅ |
| Bearer Token Authentication | |||||
clusters[].ksqlDBs[].security.token | Bearer token | CDK_CLUSTERS_0_KSQLDBS_0_SECURITY_TOKEN | false | string | ∅ |
| mTLS Authentication | |||||
clusters[].ksqlDBs[].security.key | Access key | CDK_CLUSTERS_0_KSQLDBS_0_SECURITY_KEY | false | string | ∅ |
clusters[].ksqlDBs[].security.certificateChain | Access certificate | CDK_CLUSTERS_0_KSQLDBS_0_SECURITY_CERTIFICATECHAIN | false | string | ∅ |
AuditLog export properties
The audit log can be exported to a Kafka topic, once configured in Console.| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
audit_log_publisher.cluster | The cluster ID where the audit logs will be exported | CDK_AUDITLOGPUBLISHER_CLUSTER | false | string | ∅ |
audit_log_publisher.topicName | The topic name where the audit logs will be exported | CDK_AUDITLOGPUBLISHER_TOPICNAME | false | string | ∅ |
audit_log_publisher.topicConfig.partition | The number of partitions for the audit log topic | CDK_AUDITLOGPUBLISHER_TOPICCONFIG_PARTITION | false | int | 1 |
audit_log_publisher.topicConfig.replicationFactor | The replication factor for the audit log topic | CDK_AUDITLOGPUBLISHER_TOPICCONFIG_REPLICATIONFACTOR | false | int | 1 |
Conduktor SQL properties
In order to use Conduktor SQL, you need to configure a second database to store the topics data. You can configure Conduktor SQL Database usingCDK_KAFKASQL_DATABASE_URL or set each value individually with CDK_KAFKASQL_DATABASE_*.
Configure SQL to get started.
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
kafka_sql.database.url | External PostgreSQL configuration URL in format [jdbc:]postgresql://[user[:password]@][[netloc][:port],...][/dbname][?param1=value1&...] | CDK_KAFKASQL_DATABASE_URL | false | string | ∅ |
kafka_sql.database.hosts[].host | External PostgreSQL servers hostname | CDK_KAFKASQL_DATABASE_HOSTS_0_HOST | false | string | ∅ |
kafka_sql.database.hosts[].port | External PostgreSQL servers port | CDK_KAFKASQL_DATABASE_HOSTS_0_PORT | false | int | ∅ |
kafka_sql.database.host | External PostgreSQL server hostname (Deprecated, use kafka_sql.database.hosts instead) | CDK_KAFKASQL_DATABASE_HOST | false | string | ∅ |
kafka_sql.database.port | External PostgreSQL server port (Deprecated, use kafka_sql.database.hosts instead) | CDK_KAFKASQL_DATABASE_PORT | false | int | ∅ |
kafka_sql.database.name | External PostgreSQL database name | CDK_KAFKASQL_DATABASE_NAME | false | string | ∅ |
kafka_sql.database.username | External PostgreSQL login role | CDK_KAFKASQL_DATABASE_USERNAME | false | string | ∅ |
kafka_sql.database.password | External PostgreSQL login password | CDK_KAFKASQL_DATABASE_PASSWORD | false | string | ∅ |
kafka_sql.database.connection_timeout | External PostgreSQL connection timeout in seconds | CDK_KAFKASQL_DATABASE_CONNECTIONTIMEOUT | false | int | ∅ |
| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
kafka_sql.commit_offset_every_in_sec | Frequency at which Conduktor SQL commits offsets into Kafka and flushes rows in the database | CDK_KAFKASQL_COMMITOFFSETEVERYINSEC | false | int | 30 (seconds) |
kafka_sql.clean_expired_record_every_in_hour | How often to check for expired records and delete them from the database | CDK_KAFKASQL_CLEANEXPIREDRECORDEVERYINHOUR | false | int | 1 (hour) |
kafka_sql.refresh_topic_configuration_every_in_sec | Frequency at which Conduktor SQL looks for new topics to start indexing or stop indexing | CDK_KAFKASQL_REFRESHTOPICCONFIGURATIONEVERYINSEC | false | int | 30 (seconds) |
kafka_sql.consumer_group_id | Consumer group used to identify Conduktor SQL | CDK_KAFKASQL_CONSUMER-GROUP-ID | false | string | conduktor-sql |
kafka_sql.refresh_user_permissions_every_in_sec | Frequency at which Conduktor SQL refreshes the role permissions in the DB to match the RBAC setup in Console | CDK_KAFKASQL_REFRESHUSERPERMISSIONSEVERYINSEC | false | string | conduktor-sql |
Partner Zones properties
Advanced configuration for Partner Zones.| Property | Description | Environment variable | Mandatory | Type | Default |
|---|---|---|---|---|---|
partner_zone.reconcile-with-gateway-every-seconds | The interval at which Partner Zone’s state (that’s stored on Console) is synchronized with Gateway. A lower value results in faster alignment between the required state and the current state on Gateway. | CDK_PARTNERZONE_RECONCILEWITHGATEWAYEVERYSECONDS | false | int | 5 (seconds) |
Configure HTTP proxy
Specify the proxy settings for Conduktor to use when accessing Internet. The HTTP proxy works for both HTTP and HTTPS connection. There are five properties you can set to specify the proxy that will be used by the HTTP protocol handler:CDK_HTTP_PROXY_HOST: the host name of the proxy serverCDK_HTTP_PROXY_PORT: the port number. Default value is 80.CDK_HTTP_NON_PROXY_HOSTS: a list of hosts that should be reached directly, bypassing the proxy. This is a list of patterns separated by|. The patterns may start or end with a*for wildcards, we do not support/. Any host matching one of these patterns will be reached through a direct connection instead of through a proxy.CDK_HTTP_PROXY_USERNAME: the proxy usernameCDK_HTTP_PROXY_PASSWORD: the proxy password
Example
Configure HTTPS
To configure Conduktor Console to respond to HTTPS requests, you have to define a certificate and a private key. The server certificate is a public entity that’s sent to every client that connects to the server and it should be provided as a PEM file. Configuration properties are:platform.https.cert.pathor environment variableCDK_PLATFORM_HTTPS_CERT_PATH: the path to server certificate fileplatform.https.key.pathor environment variableCDK_PLATFORM_HTTPS_KEY_PATH: the path to server private key file
Both the certificate and private key files have to allow read from user
conduktor-platform (UID 10001 GID 0) but don’t need to be readable system-wide.Sample configuration using docker-compose
In this example, server certificate and key (server.crt and server.key) are stored in the same directory as thedocker-compose file.
conduktor/conduktor-console-cortex is running as well, you have to provide the CA public certificate to the monitoring image to allow metrics scraping on HTTPS.